分类
商品









![[2D/汉化/AI汉化/PC+安卓] 低速幻想 v0.13[1.68GB]](https://pic.songma.com/upload/69459/1692102792-69459/0020714001749428722tp69459-1.jpg)





- 插入文本和图片")




")



- 商品
- 店铺
- 资讯
原本很犹豫能否要写一下这篇文章的,毕竟自己才疏学浅,说些浅的知识还行,一旦深入,就会漏了马脚。但是,另一方面想,既然知道自己懂的不够,就更应该把知道的给梳理出来,也好进行下一步的学习。所以这篇文章也算是对当前所学所知进行一个总结吧,遛。
先上一个大概的图解
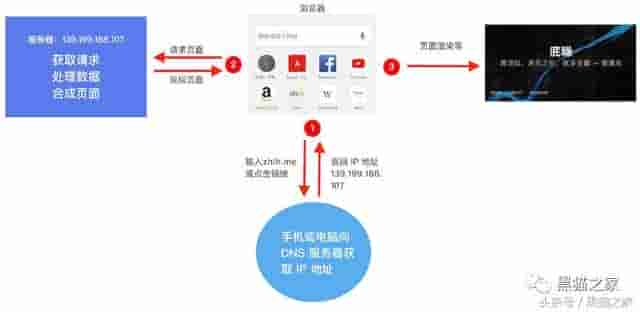
上图简单的解释了打开一个网页的过程,略微详细的解释就是:
最终就看到了网页。
从上面的简解我们可以知道,访问的过程大概可分为:URL,DNS 查询,HTTP,浏览器,这四个部分。
URL
是什么
URL 是 Uniform Resource Locator 的简写,中文:统一资源定位符,在 web 中很多时候被叫做 ‘网址’。
URL 的标准格式如下:
协议:[//地址[:端口]][/路径]文件[?数据][#锚点]- 协议: 在 web 中通常使用 http,https- 地址: 域名或者者 IP 地址- 端口: 默认情况下,http 使用 80 端口、https 使用 443 端口的时候,可以省略- 路径: 要访问资源所在的目录- 文件: 当请求的是具体一个文件时,比方一张图片,需要写清楚,否则由服务器决定返回设置的文件,一般是 `index.html`- 数据: ? 后写 GET 请求的参数,每个参数以 & 隔开,再以 = 分开参数名称与数据- 锚点: # 后面的数据不会被发送到服务器,它代表网页中的一个位置
发生了什么
浏览器获取到客户输入的 URL,就按照以上格式进行解析,假如不符合标准格式,则会判断为客户输入了关键字,并跳转到搜索引擎搜索,当 URL 中存在不是 ASCII 的字符串时,会把字符串转成 punycode 标准编码的字符串。
获取到域名后,浏览器首先会在浏览器的缓存中查找与它相关的资源,比方 DNS 缓存、静态资源缓存
浏览器的 DNS 缓存会把之前访问过的域名对应 IP 缓存起来,方便下次使用,一般会保存 TTL(DNS 服务器上缓存时间)、Expires(浏览器记录的到期时间)
假如没有缓存,则进行下一步,DNS 查询
DNS 查询
是什么
把网址翻译成 IP 地址。
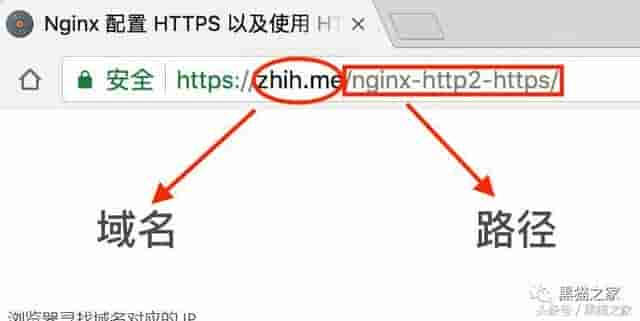
比如说你的电脑不知道 www.zhih.me 这个域名的 IP 地址,他就会向 DNS 服务器发送个请求,让 DNS 服务器帮他寻觅,此时你的电脑就是一个 DNS 用户端,实际上整个具体过程会有不同的情况。
域名的结构
想要了解 DNS 查询过程,还得先知道域名的结构。
以 www.zhih.me 这个域名为例,它是个全称域名(FQDN)
当你看到它时,应当从右往左读

而整个域名系统的结构是这样的

根域:储存了负责每个域(如com、cn、me等)的解析的域名服务器的地址信息
顶级域名(TLD):分为通用、国家、资助和地理几种类型,用于表示某些组织或者用途
二级域名(SLD):表示组织、个人、特定意义的名称
三级域名:例如:sina.com.cn,sina 是一个三级域名,同时又是 com.cn 的子域名
子域名:子域名与三级域名不同,例如:www.zhih.me,www 是 zhih.me 的子域名,但却不是三级域名
查询过程
本地解析
直接解析
本地找不到,就向你电脑里设置的 DNS 服务器请求,假如没有设置具体的地址,而是自动获取,就会从 ISP 中获取 DNS 服务器的 IP 地址,我自己使用的是腾讯的 DNS 服务器,我们一般把它叫做本地 DNS 服务器
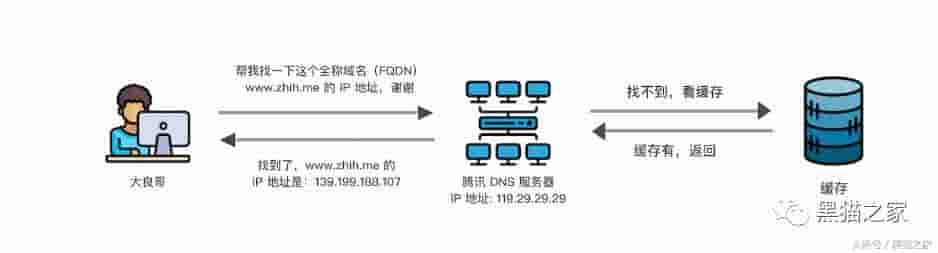
当本地 DNS 服务器找不到结果时,就需要跟其余 DNS 服务器查询获取
完整解析
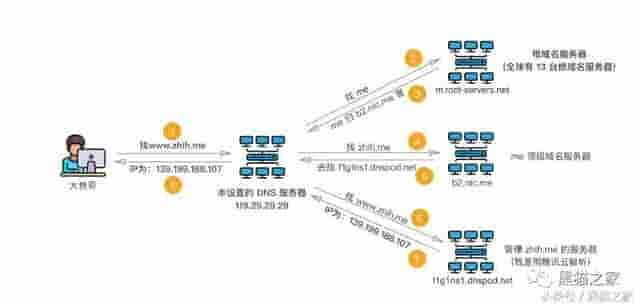
这个过程可以使用 dig 命令查看
$ dig www.zhih.me +trace
这样,电脑就拿到域名对应的 IP 地址了
HTTP
关于是什么,在维基百科已经写的很详细了,自己看看吧
https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
前面我们已经找到了 IP,那么现在我们就要发送请求和接收响应了
请求方法
方法形容
GET请求指定的页面信息,并返回实体主体
HEAD相似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST向指定资源提交数据进行解决请求(例如提交表单或者者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或者已有资源的修改
PUT从用户端向服务器传送的数据取代指定的文档的内容
DELETE请求服务器删除指定的页面
CONNECTHTTP/1.1协议中预留给能够将连接改为管道方式的代理商服务器
OPTIONS允许用户端查看服务器的性能。
TRACE回显服务器收到的请求,主要用于测试或者诊断
HTTP 状态码
HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码。它由 RFC 2616 规范定义的,并得到RFC 2518、RFC 2817、RFC 2295、RFC 2774、RFC 4918等规范扩展。
应该每个网民都不陌生,或者多或者少遇到过 404 not fount
状态码有相当多,在这里我就列出他们的分类
类型类别形容
1xx信息请求已被接受,需要继续解决
2xx成功操作被成功接收并解决
3xx重定向需要用户端采取进一步的操作才能完成请求
4xx用户端错误请求的参数错误或者无法完成请求
5xx服务器错误服务器在解决请求的过程中有错误或者者异常
HTTP 消息结构
在 shell 中使用 curl -v 命令即可以看到请求和响应的消息了
以最常用的 get 请求为例:
$ curl -v https://mov.zhih.me/weapp/list/1/2

HTTP 请求
请求报文的一般包括以下格式:请求行、请求头部、空行和请求数据
GET /weapp/list/1/2 HTTP/2//请求行: 请求方法 请求URI HTTP协议/协议版本Host: mov.zhih.me//服务端的主机名user-agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36//浏览器 UAaccept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8//用户端能接收的mineaccept-encoding: gzip, deflate, br//能否支持流压缩# 空行# 请求数据
请求头部就是请求行和空行之间的键值对
HTTP 响应
响应报文也由四个部分组成,分别是:状态行、消息报头、空行和响应正文
HTTP/2 200//状态行:HTTP协议版本号, 状态码, 状态消息server: nginx/1.14.0//web 服务器软件名及版本date: Thu, 17 May 2018 14:46:50 GMT//发送时间content-type: application/json; charset=utf-8//服务器发送信息的类型content-length: 589//主体内容长度# 空行 {"code":200,"data":[{"rank":1,"movid":1292052,"rating":9.6,"title":"肖申克的救赎","genres":["犯罪","剧情"],"year":1994,"directors":["弗兰克·德拉邦特"],"casts":["蒂姆·罗宾斯","摩根·弗里曼","鲍勃·冈顿"],"image":"https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg"},{"rank":2,"movid":1291546,"rating":9.5,"title":"霸王别姬","genres":["剧情","爱情","同性"],"year":1993,"directors":["陈凯歌"],"casts":["张国荣","张丰毅","巩俐"],"image":"https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1910813120.jpg"}]}%
//响应正文
服务器
前面说了数据怎样发送到服务器,现在说说服务器如何解决收到的数据
当然,这部分的情况相当复杂,不同场景有不同的方案,我这里只简单的举二三的例子
静态站点
我的博客 zhih.me 就是个静态站点,通过模板引擎把数据渲染成静态 HTML 文件,这些文件就存在服务器上等待下载,浏览器获取页面就是个文件下载的过程。
动态站点
这里说的动态站点,指页面是由后台解决数据合成的
常见的例子就是 WordPress,WP 应该是现在被使用得最多的 CMS 了,它的解决过程应该是这样的
前后分离站点
前后分离是现在和未来的趋势,大多数 WebApp 都是这种架构,简单说就是使用 AJAX 获取数据在用户端进行渲染。
浏览器
前面我们就是从浏览器开始的,现在又回到了浏览器,浏览器是个常用且看似简单的软件,但是讲真,原理真的挺复杂的,我这里只能说说解析和渲染相关的一点点皮毛知识,如有错误欢迎斧正。
打开浏览器开发者工具,访问一个网页,我们将看到以下信息
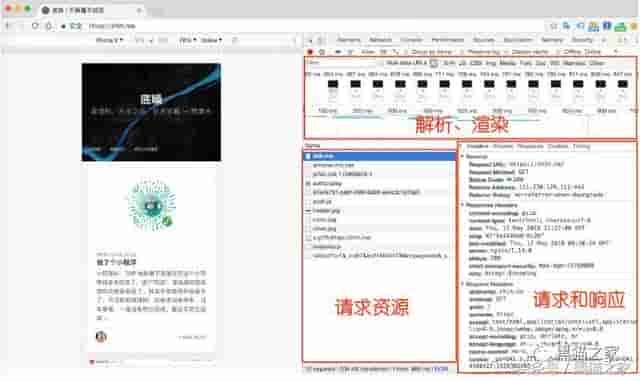
基本过程是这样的:
加载 HTML -> 解析 HTML -> 构建 DOM 树 -> 构建 CSSOM 树 -> 构建渲染树 -> 布局、绘制
但是,现代浏览器为了更快的显示页面,很多任务都是同时进行的,会一边解析 HTML,一边下载外部资源,还一边进行渲染。
解析 HTML 并构建 DOM 树
浏览器自上而下的解析 HTML 文档,并在解析的同时构建 DOM(文档对象模型) 树,DOM 树里有各个标签的属性和它们之间的关系
Critical Path Hello web performance students!
解释器深度遍历 HTML 文档,把
这些标签按照 W3C 标准,转换成 “定义它属性和规则的对象’”,而后将这些 “对象” 链接在树形结构里,这就是 DOM 树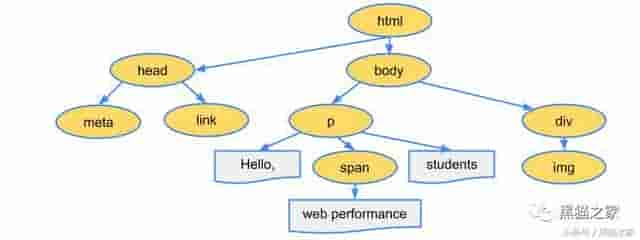
在以上 HTML 结构例子中,
和
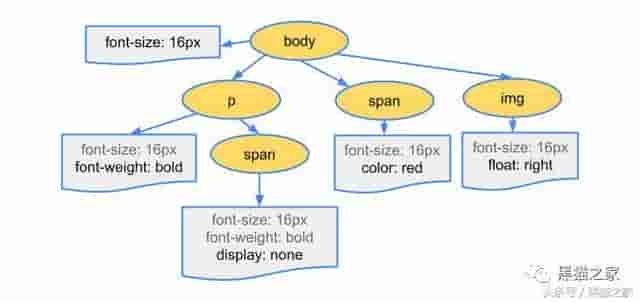
构建 CSSOM 树
在上面的 HTML 中,
里有个外部样式表 style.css,HTML 解析到这里时会向服务器请求资源,得到这样的资源:body {
font-size: 16px}p {
font-weight: bold
}span {
color: red
}p span {
display: none
}img {
float: right
}
和解决 HTML 相似,浏览器解决 CSS 构建了 CSSOM
构建渲染树
前面已经构建了 DOM 树和 CSSOM 树,现在浏览器就把它们合并成一个渲染树
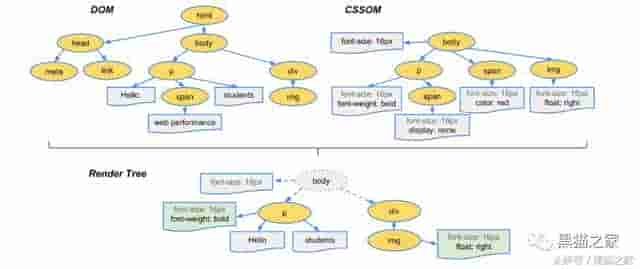
在渲染树的构建过程中,浏览器遍历 DOM 树,而后对应 CSSOM 树给每个节点设置计算样式(最终样式),设置了 display: none 的节点,将会在渲染树中移除
这样,渲染树就包含了页面上所有可见的内容和它们的计算样式
布局、绘制
渲染树只包含了内容和样式,要放到浏览器窗口中,还需要计算它们在窗口里确实切的位置和大小,这个过程叫做布局,也称为“自动重排”
浏览器从渲染树的根节点开始遍历,我们可以想象为有外向里的过程,先确定外层的位置大小,在向里层计算
布局流程的输出是一个“盒模型”,它会准确地捕获每个元素在视口内确实切位置和尺寸:所有相对测量值都转换为屏幕上的绝对像素
布局完成后,浏览器会立即发出“Paint Setup”和“Paint”事件,将渲染树中的每个节点转换成屏幕上的实际像素,这一步通常称为“绘制”或者“栅格化”
重排和重绘
当 DOM 或者 CSSOM 被修改时,会发生重排(Reflow),也就是把上面的步骤重新来一遍,这样才能确定哪些像素需要在屏幕上进行重新渲染,这个过程也被叫做回流
假如改变的属性与元素的位置大小无关,比方背景颜色,那么浏览器只会重新绘制那个元素,这个过程叫重绘(Repaint)
重排必然会引起重绘,重绘则不肯定会重排
CSS、JS 阻塞
默认情况下,CSS 是阻塞渲染的资源,浏览器需要等 DOM 和 CSSDOM 都准备好之后才会渲染,注意,这里说的是阻塞渲染,而不是阻塞 DOM 的构建,事实上 DOM 和 CSSDOM 的构建是可以同时进行的
构建 CSSOM 会阻塞它后面 JavaScript 语句的执行,而 JavaScript 语句的执行又会阻止 CSSOM 的构建,起因很简单,由于 JavaScript 执行时可能会改变 CSSOM,同时进行会对性能产生影响
除非将 JavaScript 显式公告为异步,否则它会阻止构建 DOM,由于默认情况下,浏览器遇到

 ¥108.20
¥108.20
正版火箭加注自动对接机器人设计9787515919973 郑永煌中国宇航出版有限责任公司工业技术机器人程序设计应用液体推进剂火普通大众
 ¥29.50
¥29.50
正版工业机器人系统设计及控制 : 以自动开封盖机器人为例9787109302679 刘思邦中国农业出版社工业技术
 ¥98.50
¥98.50
正版神经机器翻译/智源人工智能丛书/智能科学与技术丛书9787111701019 机械工业出版社计算机与网络自动翻系统本科及以上
 ¥19.90
¥19.90
家卫士正品全自动扫地机器人S320专用电池电芯适配趴趴走T270
 ¥5.00
¥5.00
当心自动启动标识牌注意小心机器设备操作安全警示工厂车间警告标示标志牌标语贴纸提示贴指示牌子定制DX35
 ¥20.00
¥20.00
继电器土壤湿度传感器 自动浇花 温度计检测 diy智能小车机器人

送码官方微信



















")









 手机访问领取大礼包
手机访问领取大礼包