分类
商品























- 商品
- 店铺
- 资讯
之前一篇文章实践了一下基于dify+qwenmax+rookie_text2data实现自然语言查询Mysql数据库,这个方案存在必定的缺陷,rookie_text2data这个节点基于大模型理解生成SQL时候需要去库里查询schemal,理解库表结构,给SQL输出带了不稳定性。为了改善效果,今天带来基于知识库的方案。
第一,把数据库表结构导出成txt文件,在dify知识库页面点击“创建知识库”,如下图:

选择导入已有文本,把提前导出的表结构txt文件选中,点击下一步进入如下界面:

此处,我们选择通用的分段方式,分段的长度比较重大,需要确保分段的长度能划分一个建表SQL语句,分段重叠长度主要指前后两段重合度。
索引方式我们选择高质量,Embedding模型选择通义的text-embedding-v3,检索设置中Rerank模型选择gte-rerank,点击保存处理后,就会自动分段,并对分段后的内容进行向量化处理。
接下来,我们新建一个chatflow,在开始节点后新增一个知识库节点:
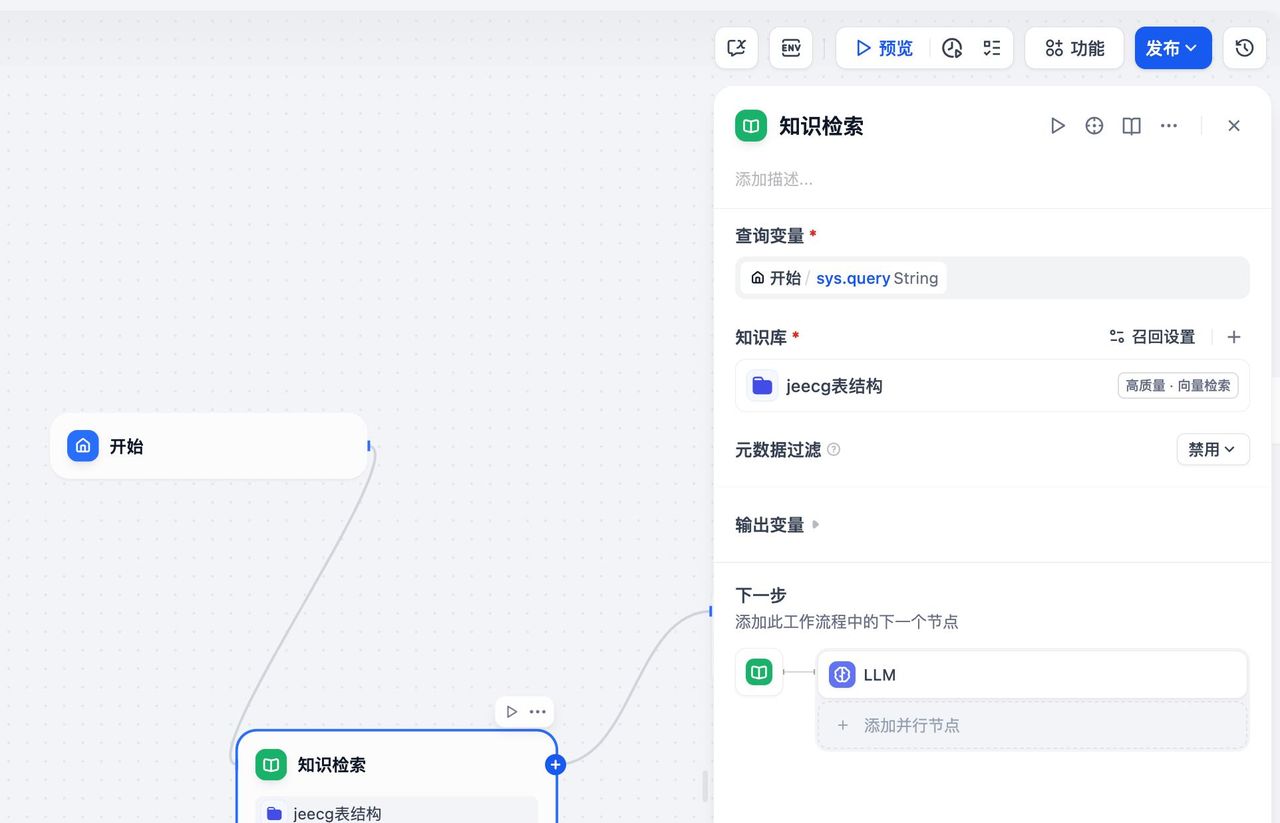
查询变量设置sys.query,知识库选择我们刚刚新建的表结构知识库,输出变量使用默认即可;
在知识库节点后增加一个大模型节点,用于把知识库命中的结果发送给大模型,让大模型生成待执行的SQL:

上下文选择知识库输出的结果,提示词中需要把知识库的输出结果也加入,模型节点输入内容默认text类型;
下面再增加一个代码执行节点,用于从大模型返回的结构化的json中提取出来SQL:

到此节点输出的就是一个可执行的SQL,我们再新增一个工具,选择rookie_execute_sql来执行SQL,获取执行结果给到输出即可。

下面为了演示图表生成能力,新增了两个节点,一个代码执行节点把SQL执行结果转成图表要用的格式:
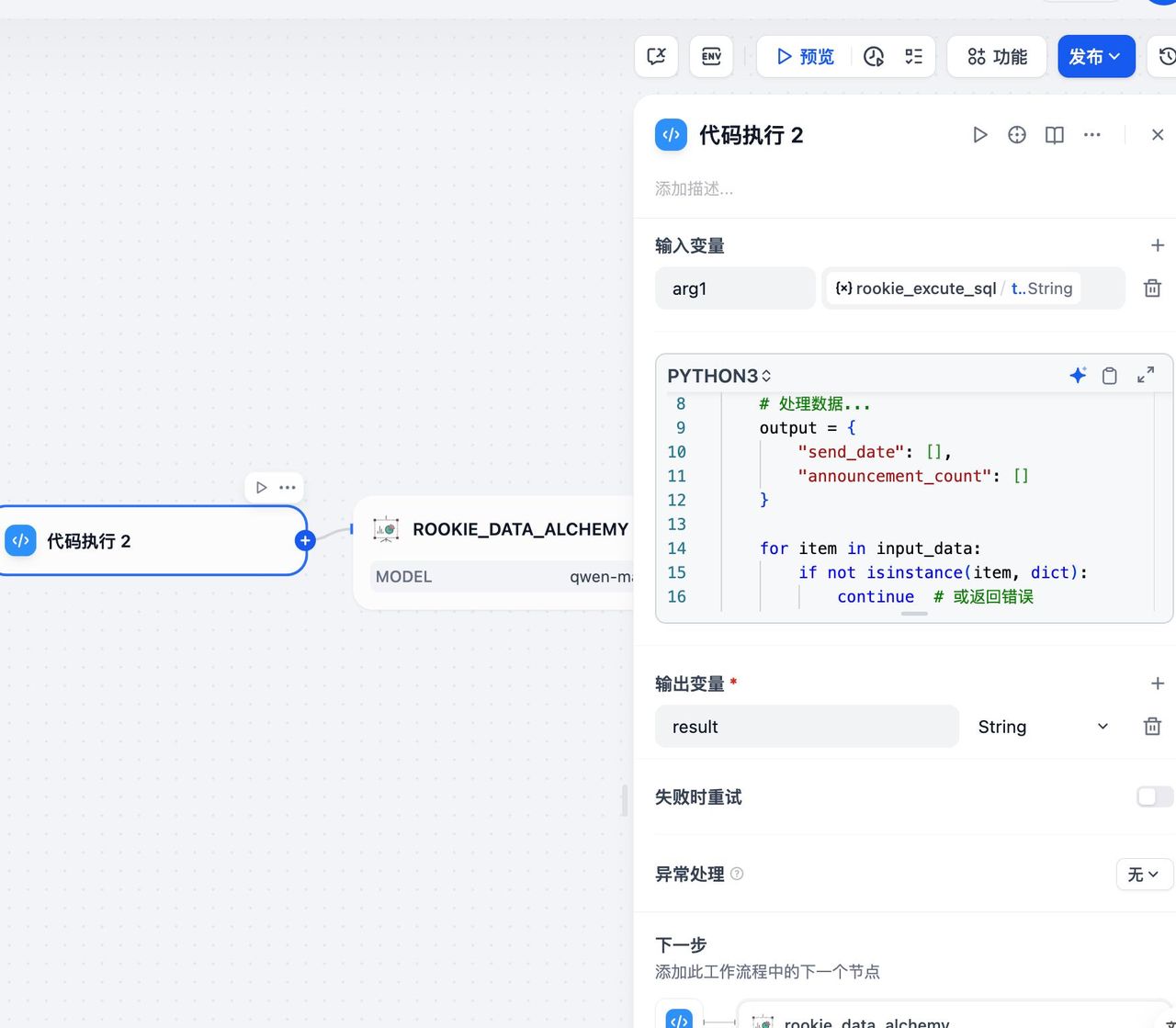
一个工具节点,在插件市场安装rookie_data_alchemy后即可使用

最终呈现的效果如下:



送码官方微信















")

















 手机访问领取大礼包
手机访问领取大礼包