二开/独开/特色
QQ非主流/图片
电影/视频/音乐
游戏/动漫/竞技
聊天/交友/直播
小说/文章/文学
医院/女人/健康
导航/网址/查询
淘客/网店/商城
门户/新闻/资讯
热门推荐
软件工具
社交推广
苹果APP
安卓APP
视频教程
其他
PC游戏
主机游戏
手机游戏
邀请码
CDK
网站建设
APP开发
定制仿站
SEO优化
推广外链
安装迁移
软件开发
游戏开发
代办服务
windows
Linux
数据库
软件环境
服务器应用
CSS
HTML
JS
登录
注册
3D 轮转照片
BUI 后台管理模板
CSS 实现图片轮播
简单有趣的后台登录页面模板
HTML5+CSS3骑车动画场景
html5 粽子大战 小游戏源码











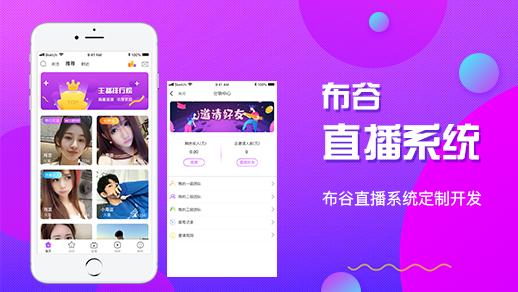

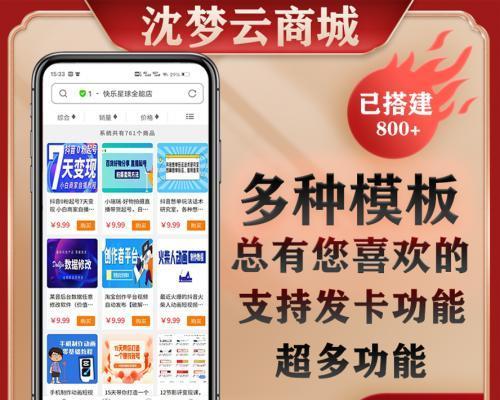
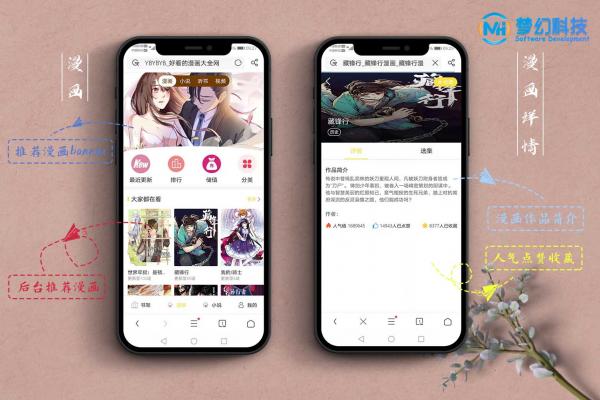


 杀死队友")




")
——每天几个样式,轻松玩转CSS")





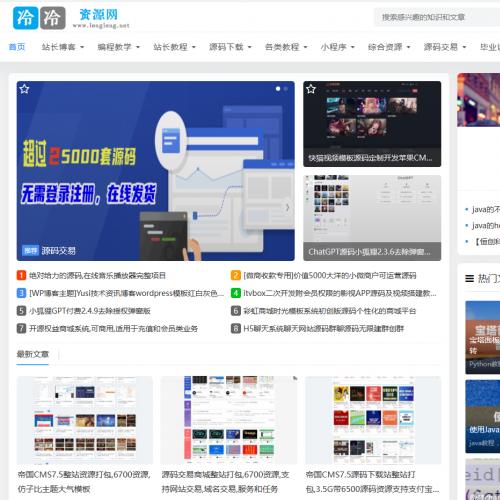

















")










 手机访问领取大礼包
手机访问领取大礼包