分类
商品














 杀死队友")




")
——每天几个样式,轻松玩转CSS")


- 商品
- 店铺
- 资讯
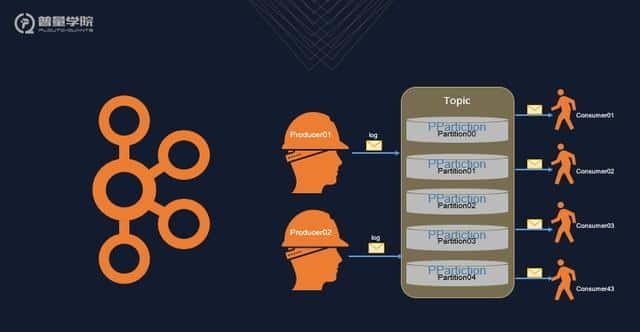
本次我们分享的内容是基于消息系统的分布式量化交易系统,主要是讲Kafka的实际应使用。Kafka是一个分布式的发布-订阅消息系统,它最初由LinkedIn开发,开源之后,不久成为Apache的顶级项目,现在众多大型平台都在用,比方阿里云就提供基于Kafka的消息中间件服务。这张图就是Kafka的一个基本场景,最左端是Producer,也就是生产者,多个生产能生成统一类别的消息,在Kafka的术语里,消息又被称为log。所谓同一类别,也就是同一个topic。从图上能看出,一个Topic能分为多个partition,这些partition能在一台主机上,也能在分布在多台主机上,这些多台主机之间的同步由zookeeper来保证。图上最右侧就是多个consumer,也即是说同一个topic,能被多个consumer订阅。每一个consumer都会在kafka服务器注册,Kafka服务器会维持每一个consumer已经耗费的消息的偏移量。因而Kafka能完全保证,每一个consumer都能按照时序消费所有消息。对Kafka的基本概念和用方法,不是特别理解的同学,能参考我们的其余课程,或者者参阅官方文档。我们这次课,主要是和各位同学分享Kafka在量化交易系统中的所发挥的重要作使用。
一 场景:行情数据分发
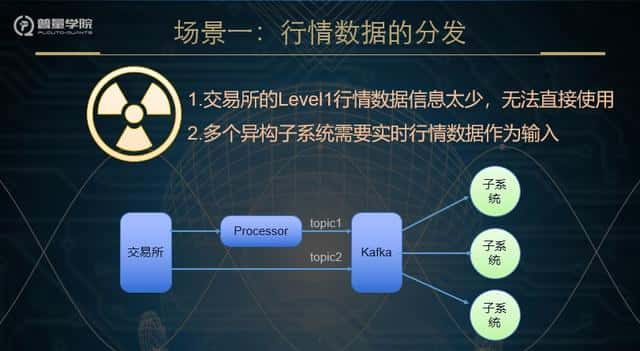
我们面临的第一个问题就是行情数据的解决,行情数据是量化交易系统最基本的输入数据,但是,从交易所过来的Level1并不可以直接用,是由于它里面包含的信息太少,只有当前这个时刻的高、开、低、最新价、成交量、成交额、买五和卖五等。大家能去上交所和深交所的网站上查看官方文档,里面有详细的详情。所以我们首先要对这些原始行情数据进行解决,比方聚合为分钟线。第二个要处理的问题,普量云的量化交易系统里面包含了很多子系统,这些子系统也需要行情数据作为输入。看到这些问题,有些同学,一定立即又想到了,利使用数据库作为数据的中转站。确实,刚开始我们也是这样用的,可是很快就出现了瓶颈,对数据库的压力太大。Level1的行情数据是每3秒升级一次,算上指数,大概有6000多条记录,再加上不同系统的同时读写,可想而知,对数据库造成的压力有多大。其实,那么这种场景就是Kafka最基本的应使用场景。(出图)交易所过来的数据,作为一个topic直接进入Kafka,经过Processor解决的数据,作为另外一个topic进入Kakfa。那么各个子系统,即可以根据需求订阅topic1、topic2,或者者二者都有。通过这种改造以后,推迟降到了毫秒级别。
二 场景:模拟盘数据流
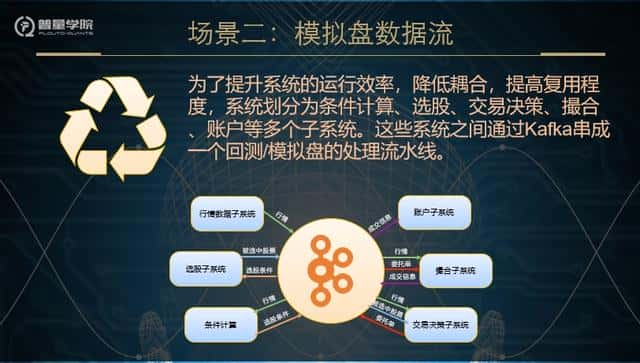
量化的交易过程一般包括了条件计算、选股、交易决策、撮合等多个步骤,因而假如只是做试验,可可以只要要一个脚本既能一律包括了。而普量云是将这些功可以封装为不同的子系统,从而提高策略验证的运行效率,也降低了耦合。那么这些系统之间的数据交换就是一个需要处理的问题。一种可选方式就是每个子系统提供一套API,供相关系统调使用,这很符合微服务的设计理念。可是这样无疑会添加很多和子系统核心功可以无关的开发工作,也加重了后期维护的代价。另外一种可选的方式,当然还是数据库,在回测或者者模拟盘运行过程中,系统之间的数据交换十分频繁,数据量也比较大。另外,随着回测的次数的增多,那么数据库就会急剧膨胀。至此,无需再深入分析,数据库似乎不太现实。因而我们还是考虑用Kafka作为数据流转的中枢。
三 场景:任务触发器
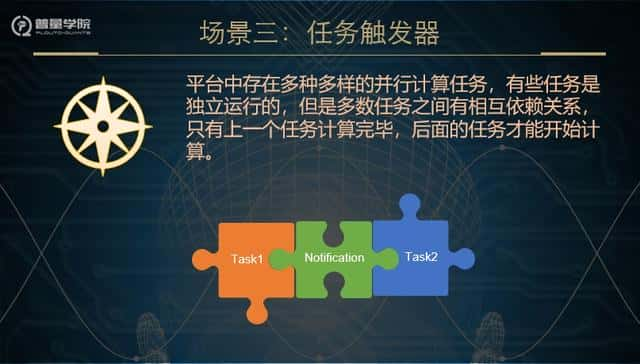
分布式的量化交易系统中可可以包含了上百个不同的计算任务。这些任务有些独立运行的,有些是有相互依赖关系的。一个任务只有它依赖的任务计算完,这个任务才可以执行。一种处理方案就是把任务的运行状态写入数据库中,后执行的任务就不断的轮询它依赖的任务的状态,直到前面的任务执行完毕。可是,这种做法很显然效率极低,因而还是使用Kafka作为任务的触发器。例如,Task1计算完后,就会发送一个notification到Kafka,Kafka就把订阅了这些notification的任务,比方task2,task2收到这个通知后,就开始计算。
上面就是Kafka在普量云中三种典型运使用场景。在用的过程,我们也遇到了不少问题,我相信其余同学也可可以会遇到这些问题,那么我们就来看这些问题。

好了,今天的内容就详情到这里,希望今天的内容对你有所帮助!


送码官方微信



















")













 手机访问领取大礼包
手机访问领取大礼包