
本次老K给大家带来的AI模型是开源视觉模型Qwen2.5-VL,Qwen2.5-VL是阿里通义千问于2025年1月28日开源的视觉语言模型,属于Qwen模型家族的旗舰产品。该模型推出了3B、7B和72B三个尺寸版本。由于要使用本地笔记本进行测试,所以选择最小的3B模型。
本次环境搭建测试不需要代码编写能力,不需要GPU的配置,直接使用提示词的方式进行测试。测试环境为windows11+Ollama+Cherry Studio。
Ollama是什么?ollama 是一个本地大模型运行工具(LLM runtime + 管理工具),它的定位类似于一个简化的本地化模型管理器,可以在个人电脑上快速下载、运行和管理各种开源大模型。Ollama 可以在纯 CPU 环境下运行,只是推理速度会比较慢,如果有GPU会自动选择GPU。
登录ollama官方网站,选择windows版本,进行下载即可。也可以直接访问以下地址:
https://ollama.com/download/OllamaSetup.exe。
安装Ollama(如果不切换路径,全部下一步就可以)

Ollama安装
安装后打开主页,直接在右下角筛选qwen2.5vl:3b。

选择模型
第一次使用会自动下载模型,不需要再使用命令行进行下载。(当然也可以用命令行下载,在CMD中输入命令:ollama rm qwen2.5vl:3b,自动完成下载)

模型自动下载
下载成功后,进行语言对话,(明显翻车进入死循环,后面一直重复泰文、越南文、印尼文,先暂停,我们只让它处理图像识别功能)

对话测试(翻车)
登录官方网站(
https://www.cherry-ai.com/),下载windows版本,进行安装。
安装后打开页面如下图

Cherry-Studio
点击右上角小齿轮进行设置,来修改模型。

增加本地模型
点击添加按钮,添加模型,模型ID输入:qwen2.5vl:3b ,其他默认会自动回显。

增加qwen2.5vl:3b
添加成功后,在进行编辑模型,修改模型类型为视觉。

编辑模型属性
点击“更多设置”,选择视觉,然后进行保存。
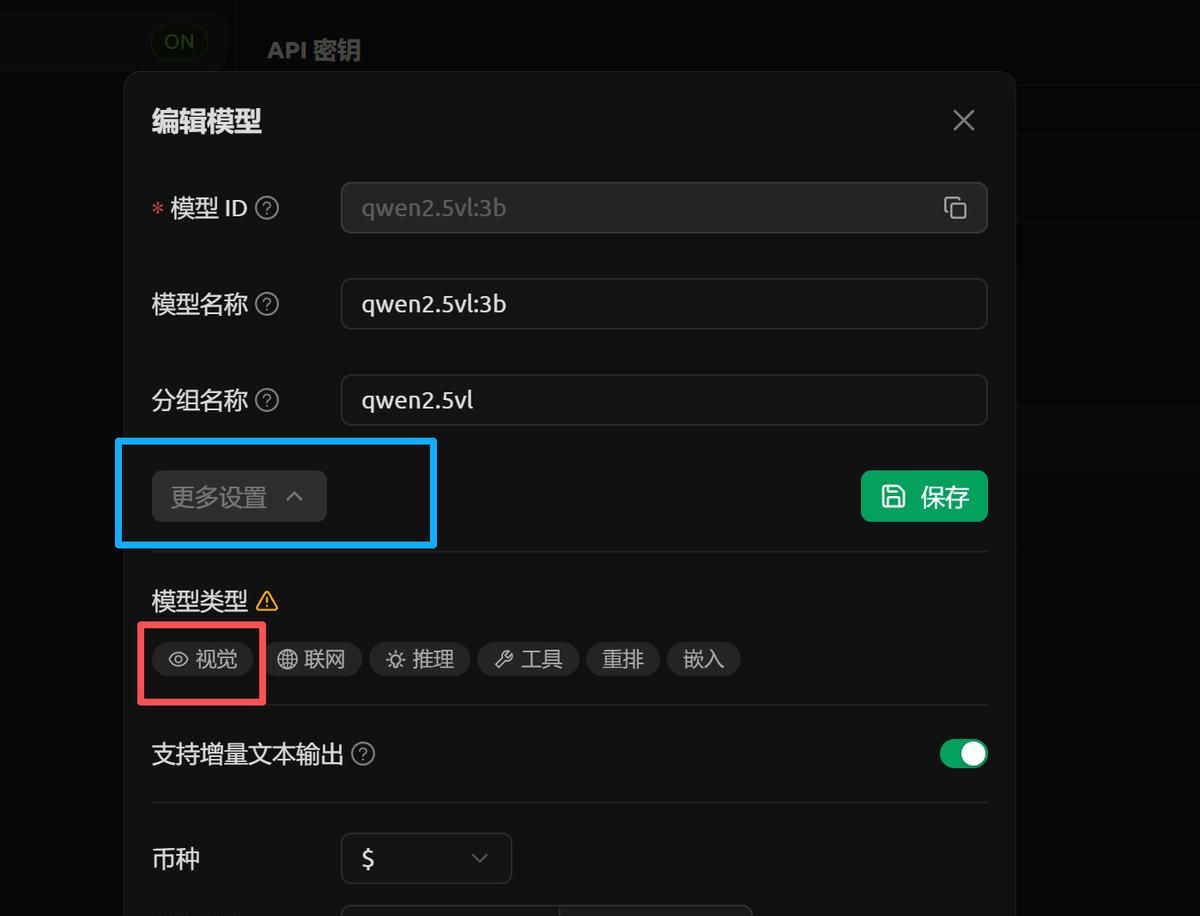
选择视觉,保存
最终有一个小眼镜在模型名称旁边显示,证明修改成功。

编辑模型后
点击检测功能,检测模型是否正常运行。

进行测试
提示连接成功,同时检测按钮变为小对号。最后别忘记最右上角的打开按钮。
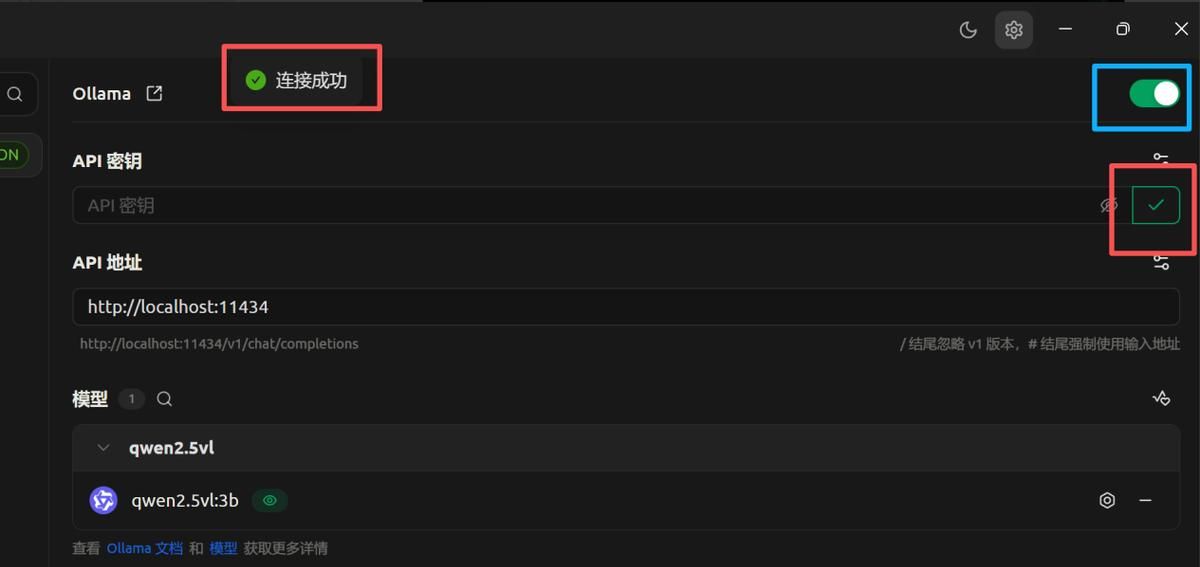
测试成功结果
通过百度随机搜索一张票据,百度图片搜索一下。

一张随机的票据
,回到首页-默认助手,选择最上面的模型列表,选择咱们刚刚新增的qweb2.5vl:3b|ollama。

选择刚刚添加的模型
推理前先看一下机器的性能,推理后看一下变化。

CPU和内存的变化
上传票据图片,输入提示词:请帮我描述一下上传的图片,并使用JSON格式返回描述信息。
下图为推理中的CPU和内存的变化,ollama在识别不了GPU的情况下,默认走CPU进行推理。

CPU和内存的变化
推理的结果如下图(没有针对性的提示词,返回了一些主要的数据)

返回JSON数据
修改一下提示词:请从图片中识别发票代码、发票号码、金额、日期,识别结果通过json格式返回,日期使用YYYY-MM-DD格式。

返回JSON数据
右下角是token和处理的时间,第一次比较慢,后续变得更快了。

返回JSON数据
咱们测试的是3B的模型,识别可能还是很不错的,当然需要大量的测试才可以得到最终的验证结果,我信任模型越大识别的效果会越好。大模型对硬件要求也很高,效果和成本需要平衡去思考。
老K发现随着大模型的发展,之前传统的智能工具(如生物识别、图像识别)最终会被大模型替代,大模型具备通用的标准能力。随着新材料和新硬件的突破,信任算力问题会被解决,也许后来大模型同目前操作系统一样,成为一个底层的软件平台,普通PC会可以进行安装使用。最后祝国内开源模型越来越好。
