
引: 之前写过一篇文章详情如何管理linux设施上的bridge(网桥)和docker bridge, 今天我们来看看k8s的网络模型。
我们先来看图示例,下面则个是k8s的网络模型图。
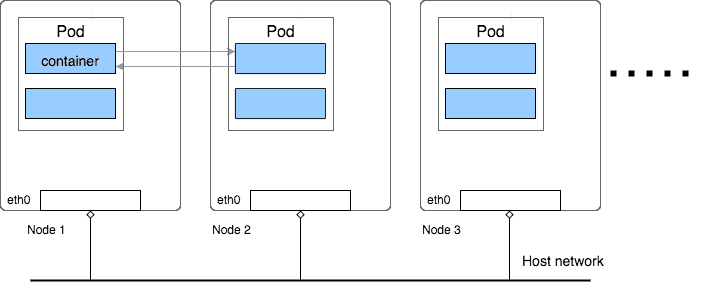 k8s的网络模型
k8s的网络模型我们知道,在k8s里面最小的管理单元是pod,一个主机可以跑多个pod,一个pod里面可以跑多个容器。
如上面所示,一个pod里面所有的容器共享一个网络命名空间(network namespace),所以,pod里面的容器之间通信,可以直接通过localhost来完成,pod里面的容器之间通过localhost+端口的方式来通信(这和应用程序在宿主机的通信方式是一样的)。
那么pod和pod之间的通信呢?通常来说,我们给应用程序定死端口会给应用程序水平扩展带来很多不便,所以k8s不会使用定死端口这样的方法,而是采用其余方法来处理pod之间寻址的问题
每个pod都会有一个自己的ip,可以将Pod像VM或者物理主机一样对待。这样pod和pod之间的通信就不需要像容器一样,通过内外端口映射来通信了,这样就避免了端口冲突的问题。
特殊的情况下(比方运维做网络检测或者者程序调试),可以在pod所在的宿主机想向pod的ip+端口发起请求,这些请求会转发到pod的端口,但是pod本身它自己是不知道端口的存在的。
因而,k8s的网络遵循以下准则:
把上面这个pod替换成容器也是成立的,由于pod里面的容器和pod共享网络。
基本上的准则就是,k8s的里面的pod可以自由的和集群里面的任何其余pod通信(即便他们是部署在不同的宿主机),而且pod直接的通信是直接使用pod自己的ip来通信,他们不知道宿主机的ip,所以,对于pod之间来说,宿主机的网络信息是透明的,如同不存在一样。
而后,定了这几个准则之后,具体的实现k8s的这个网络模型有好多种实现,我们这里详情的是Flannel,是其中最简单的一种实现。
Flannel实现pod之间的通信,是通过一种覆盖网络(overlay network),把数据包封装在另外一个网络来做转发,这个覆盖网络可以给每一个pod分配一个独立的ip地址,使他们看起来都是一台具备独立ip的物理主机一样。
下面这个就是k8s用覆盖网络来实现的一个例子:
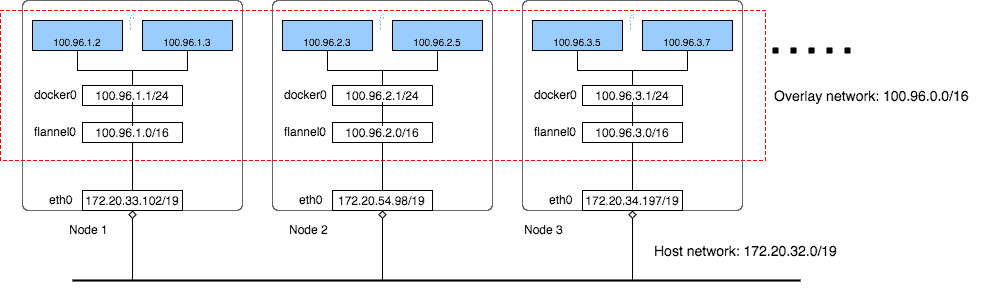 flannel覆盖网络
flannel覆盖网络可以看到有3个node,在多个node上建立一个覆盖网络,子网网段是100.95.0.0/16,而后,最终到容器级别,每个容器在这个网段里面获取到一个独立的ip。而宿主机所在的局域网络的网段是172.20.32.0/19
看这两个网段,就知道,fannel给这个集群创立了一个更大的网络给pod使用,可以容纳的主机数量达到65535(2^16)个。
对于每个宿主机,fannel给每个了一个小一点的网络100.96.x.0/24,提供给每个这个宿主机的每一个pod使用,也就是说,每一个宿主机可以有256(2^8)个pod。docker默认的网桥docker0用的就是这个网络,也就是所有的docker通过docker0来使用这个网络。即便说,对于容器来说,都是通过docker0这个桥来通信,和我们平时单机的容器是一样的(假如你不给创立的容器指定网络的话,默认用的是docker0,参考我以前写的关于docker bridge的文章)
那么,对于同一个host里面的容器通信,我们上面说了是通过这个台宿主机的里面的docker0这个网桥来通信。那对于跨宿主机,也即是两个宿主机之间的容器是怎样通信的呢?fannel使用了宿主机操作系统的kernel route和UDP(这是其中一种实现)包封装来完成。下图演示了这个通信过程:
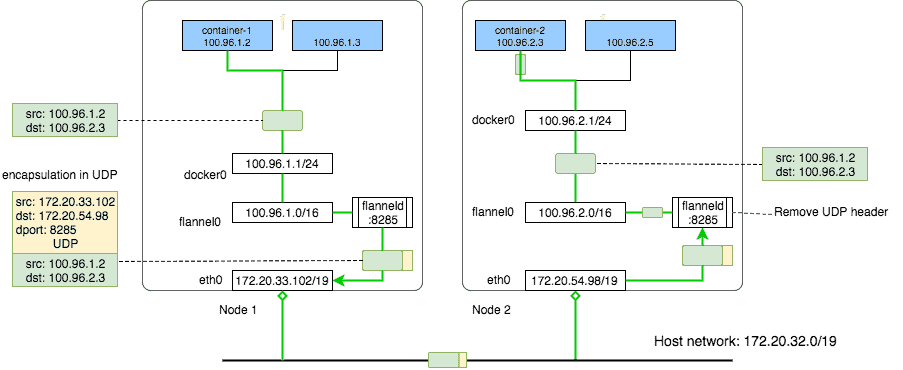 fannel网络中跨宿主机的容器通信
fannel网络中跨宿主机的容器通信如图所示,100.96.1.2(container-1) 要和100.96.2.3(container-2)通信,两个容器分别处于不同的宿主机。
假设有一个包是从100.96.1.2发出去给100.96.2.3,它会先经过docker0,由于docker0这个桥是所有容器的网关。 而后这个包会经过route table解决,转发出去到局域网172.20.32.0/19. 而这个route table的对应解决这类包的规则又是从哪里来的呢?它们是由fannel的一个守护程序flanneld创立的。
每一台宿主机都会跑一个flannel的deamon的进程,这个进程的程序会往宿主机的route table里面写入特定的路由规则,这个规则大概是这样的。
Node1的route table
admin@ip-172-20-33-102:~$ ip routedefault via 172.20.32.1 dev eth0100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1172.20.32.0/19 dev eth0 proto kernel scope link src 172.20.33.102图例的数据包发出去的目标地址是100.96.2.3,它属于网段100.96.0.0/16,这个目标地址命中第二条规则,也就是这个包会发到flannel0这个设施(dev),这flannel0是一个TUN设施。是在内核里面的一个虚拟网络设施(虚拟网卡)。
在内核(kernel)里面,有两种虚拟网卡设施,分别是TUN和TAP,其中TAP解决的是第二层(数据链路层)的帧,而TUN解决的是第三层(网络层)的ip包。
应用程序可以绑定到TUN和TAP设施,内核会把数据通过TUN或者者TAP设施发送给这些程序,反过来,应用程序也可以通过TUN和TAP向内核写入数据,进而由内核的路由解决这些发出去的数据包。
那么上面这个flannel0就是一个这样的TUN设施。这个设施连到的是一个flannel的守护进程程序flanneld
而这个flanneld是干嘛的呢?它可以接受所有发往flannel0这个设施的数据包,而后做数据封装解决,它的封装的逻辑也很简单,就是根据目标地址,找到这个这地址对应的在整个flannel网络里面对应物理ip和端口(这里是Node2对应的物理ip),而后添加一个包头,添加的包头里面目标地址为这个实际的物理ip和端口(当然源地址也改成了局域网络的ip),将原来的数据包嵌入在新的数据包中,而后再把这个封装后的包扔回去给内核,内核根据目标地址去路由规则匹配规则,发现目标地址ip是172.20.54.98,端口是8285. 根据ip匹配不到任何特定的规则,就用第一条default(默认)的规则,通过eth0这个物理网卡,把数据包发给局域网(这里是UDP广播出去)
当Node2的收到这个包后,而后根据端口8285发现他的目标地址原来是发给flanneld的,而后就直接交给flanneld这程序,flanneld收到包后,把包头去掉,发现原来目标地址是100.96.2.3,而后就交换flannel0,flannel0把这个解开后的原包交给内核,内核发现它的目标地址是100.96.2.3,应该交给docker0来解决。(图例里面画的是直接由flannel0交给docker0,没有图示出内核,实际上flannel0是一个TUN设施,是跑在内核的,数据经过它后可以交给内核,由内核根据路由决定进一步怎样forward)
以上就是这个通信的过程,那么这里有一个问题: flanneld是怎样知道100.96.2.3对应的目标地址是172.20.54.98:8285的呢?
这是由于flanneld维护了一个映射关系,它没创造一个虚拟的容器ip(分配给容器新ip的时候),它就知道这个容器的ip实际上是在哪台宿主机上,而后把这个映射关系存储起来,在k8s里面flanneld存储的这个映射关系放在etd上,这就是为什么flanneld为什么知道这个怎样去封装这些包了,下面就是etcd里面的数据的:
admin@ip-172-20-33-102:~$ etcdctl ls /coreos.com/network/subnets/coreos.com/network/subnets/100.96.1.0-24/coreos.com/network/subnets/100.96.2.0-24/coreos.com/network/subnets/100.96.3.0-24admin@ip-172-20-33-102:~$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24{"PublicIP":"172.20.54.98"}看上面这个数据,etcd里面存储的100.96.2.0-24这个网段的容器是放在172.20.54.98这台宿主机上的。
那么还有一个问题,端口8285又是怎样知道的?
这个很简单,flanneld的默认监听的端口就是这个8285端口,flanneld启动的时候,就监听了UDP端口8285. 所以发给Node2:8285的所有UDP数据包会,flanneld这个进程会直接解决,如何去掉包头就复原出来原来的包了,复原后交给TUN设施flannel0,由flannel0交给内核,内核根据Node2的路由规则交给docker0(Node2的路由规则和node1是基本上一样的,除了第三位的网段标识不一样,一个是100.96.1一个是100.92.2):
admin@ip-172-20-54-98:~$ ip routedefault via 172.20.32.1 dev eth0100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.2.0100.96.2.0/24 dev docker0 proto kernel scope link src 100.96.2.1172.20.32.0/19 dev eth0 proto kernel scope link src 172.20.54.98看Node2的这个规则,flannld去掉包头解出来的原包的目标ip是100.96.2.3,由flannel0交回去给kennel,kennel发现命中第三条规则,所以会把这个包叫给docker0,继而就进入了docker0这个桥的子网了,接下去就是docker的事情了,参考以前写的文章。
最后一个问题,怎样配置docker去使用100.96.x.0/24这个子网呢,假如是手工创立容器的话,这个也是非常简单的,参考以前写的关于docker bridge的这篇文章,但是在k8s里面,是通过配置来实现的:
flanneld会把子网信息写到一个配置文件/run/flannel/subnet.env里
admin@ip-172-20-33-102:~$ cat /run/flannel/subnet.envFLANNEL_NETWORK=100.96.0.0/16FLANNEL_SUBNET=100.96.1.1/24FLANNEL_MTU=8973FLANNEL_IPMASQ=truedocker会使用这个配置的环境变了来作为它的bridge的配置
dockerd --bip=$FLANNEL_SUBNET --mtu=$FLANNEL_MTU以上,就是k8s如何使用flannel网络来跨机器通信的原理,总体来讲,因为flanneld这个守护神干了所有的脏活累活(其实已经是k8s的网络实现里面最简单的一种了),使得pod和容器能够连接另外一个pod或者者容器变得非常简单,就像连一个大局域网里面任意以太主机一样,他们只要要知道对方的虚拟ip即可以直接通信了,不需要做
NAT等复杂的规则解决。
那么性能怎样样?
新版本的flannel不推荐在生产环境使用UDP的包封装这种实现。只用它来做测试和调试用,由于它的性能体现和其余的实现比差少量。
 flannel0 利用的TUN设施做包封装原理
flannel0 利用的TUN设施做包封装原理看上面这个图解,一个upd包需要来回在客户空间(user space)和内核空间(kennel space)复制3次,这会大大添加网络开销。
官方的文档里面可以看到其余的包转发实现方式,可以进一步阅读,其中host-gw的性能比较好,它是在第二层去做数据包解决。
