
使用spark读写es可以使用ES提供的包,es提供了对hadoop,spark等大数据组件的包,es-spark包地址:https://www.elastic.co/guide/en/elasticsearch/hadoop/6.3/spark.html
项目中有两个索引数据量较大,尽管API支持读前过滤,但是过滤后的数据读起来还是很慢。本身指标计算不复杂,计算时间很短,读数据成为短板。
| 索引名 | shard数 | 数据量 | 过滤后 |
|---|---|---|---|
| leads | 5 | 7千万 | 1千万 |
| leads_call | 5 | 9千万 | 100万 |
1.优化查询
使用spark.sparkContext.esRDD(esResource(esIndex), query)读的数据,发现自己的rangeQuery还不如matchAllQuery读的快,发现es在根据字段进行range查询时,假如这个range不是数字(可能还有其余类型)类型,查询本身就很慢。
2.优化es-rdd读取方式
更改索引的mapping后,速度确实提升很多,但是读数据仍然是短板。
从文档中发现,改了如下参数
spark.es.scroll.size=10000
spark.es.input.use.sliced.partitions=false
scroll.size默认设置如同才10,读数据是走的http,我过滤后的数据有1千万多
第二个参数是关闭slice优化,默认是打开的,会根据索引的数据量
和spark.es.input.max.docs.per.partition大小划分分区,默认每个分区是10万。
经测试发现,假如不关闭slice优化,且走这个默认值,读的esRDD确实会有多个分区,也会有多个task并发读,但是task太多反而耽误了速度,读得较慢。
在关必slice优化的情况下,分区数为shard数,读leads索引耗时2.4min左右,快了不少。
3.添加executor数,提供读数据的并发度。
因为指标需要5min升级一次,整个计算过程耗时4min左右,读数据上还需要提速。
因为spark中的stage没有依赖关系可以并发执行,添加executor后,两个索引同时读取。

4.打开slice优化/添加shard数
即便提高任务的并发度,但是读leads索引的stage仍然太慢。目前是5个分区在并发读,在打开slice优化,并设置每个分区为文档数为100万后
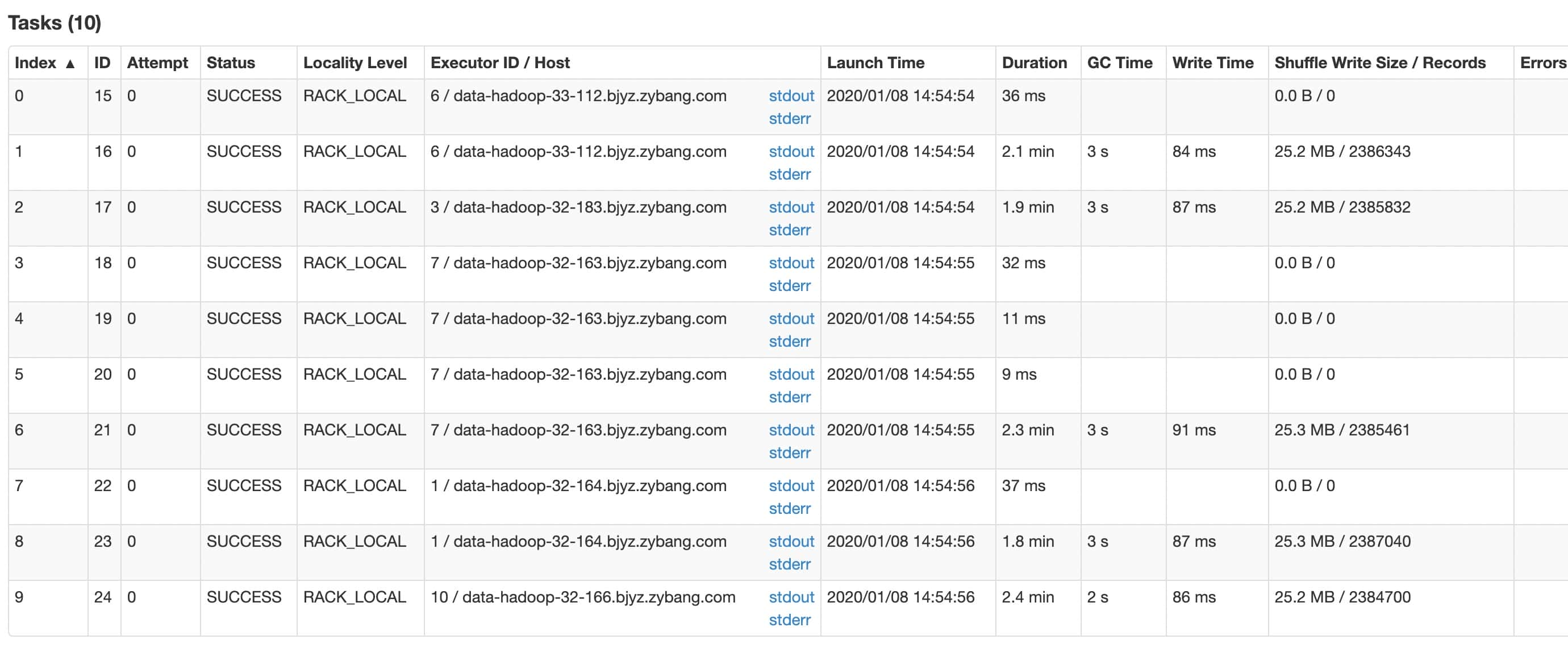
尽管分区数提高了,但是数据分布并不均匀,造成这种现象可能和多种因素有关。
因为slice优化不理想,这里采取添加索引shard数的方式,将shard加至10,并且关闭slice优化,效果比较理想。
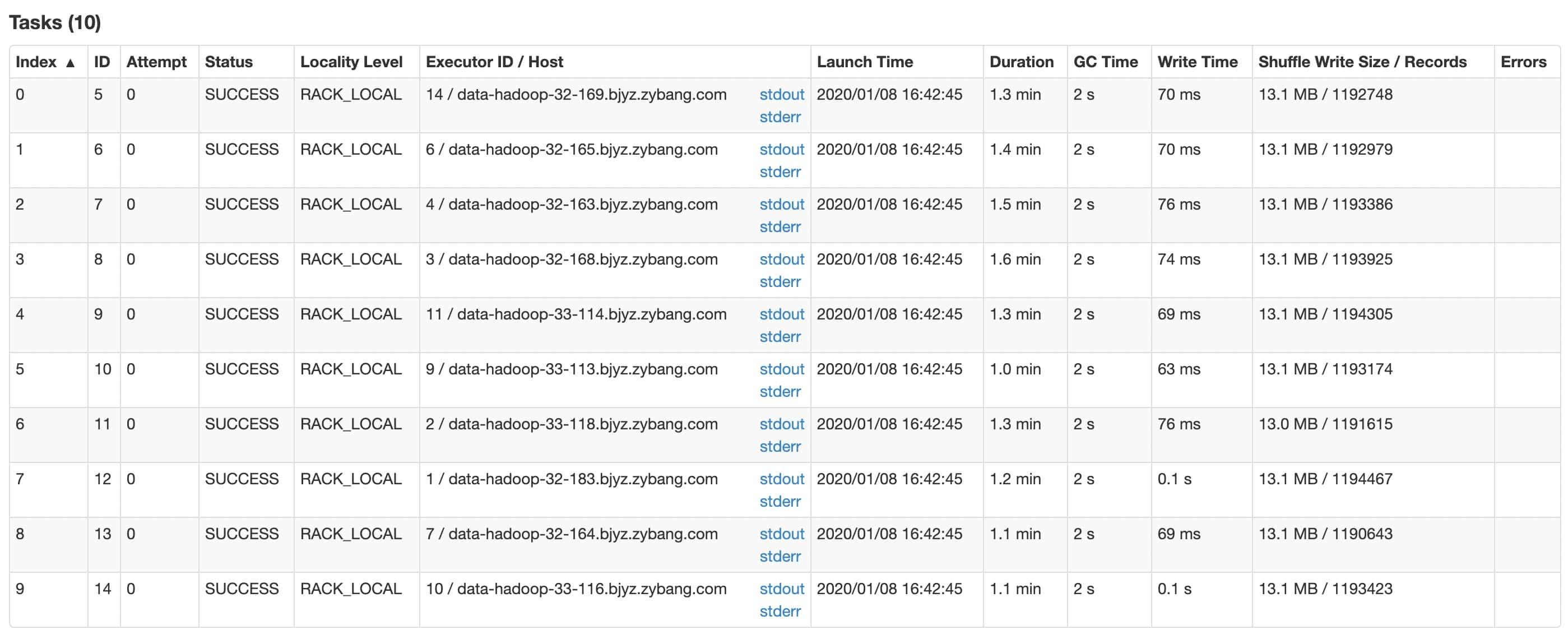
项目中数据经过聚合计算后,数据量只有100万左右,因而写数据并不是短板,只是简单配置了参数。
spark.es.batch.size.entries=5000
spark.es.batch.write.refresh=false
第一个参数设置批写入的bulk大小,默认值是1000,
第二参数关闭批写入后主动刷新索引的操作
经过层层优化,整个计算任务控制在了3min中左右,任务时间得到缩短,但是读数据仍然占的比重较大,个人感觉es本身并不适合大批量数据读写的场景。假如执行计算任务的数据量很大,es和spark并不搭,可以考虑Hbase+spark的方式替代。反之,假如数据可以提前过滤,并且过滤后的数据并不多的情况下,使用es+spark是一种不错的选择。
