
推荐阅读:揭开面纱,追着 redis 七连问!
对于web来说,是客户量和访问量支持项目技术的更迭和前进。随着服务客户提升。可能会出现一下的少量状况:
页面并发量和访问量并不多,mysql足以支撑自己逻辑业务的发展。那么其实可以不加缓存。最多对静态页面进行缓存就可。
页面的并发量明显增多,数据库有些压力,并且有些数据升级频率较低反复被查询或者者查询速度较慢。那么即可以考虑使用缓存技术优化。对高命中的对象存到key-value形式的redis中,那么,假如数据被命中,那么可以省经效率很低的db。从高效的redis中查找到数据。
当然,可能还会遇到其余问题,你可以需要静态页面本地缓存,cdn加速,甚至负载均衡这些方法提高系统并发量。这里就不做详情。
我们从一个算法问题开始理解缓存的意义。
问题1:输入一个数n(n<20),求n!;
分析1:单单考虑算法,不考虑数值越界问题。当然我们知道n!=n * (n-1) * (n-2) * ... * 1= n * (n-1)!;那么我们可以用一个递归函数处理问题。

这样每输入求一次需要执行n次。
问题2:输入t组数据(可能成百上千),每组一个x(n<20),求x!;
分析2:


时间复杂度才O(n)。这里的思想就和缓存思想差不多。先将数据在jiecheng[21]数组中储存。执行一次计算。当后面继续访问的时候就相当于当问静态数组值。为O(1)。就能大大的减少查询、执行成本啦!

缓存适用于高并发的场景,提升服务容量。主要是将从经常被访问的数据或者者查询成本较高从慢的介质中存到比较快的介质中,比方从硬盘—>内存。我们知道大多数关系数据库是基于硬盘读写的,其效率和资源有限,而redis等非关系型就是基于内存存储。其效率差别很大。当然,缓存也分为本地缓存和服务端缓存,这里只讲redis的服务端缓存。
举个例子。例如假如一个接口sql查询需要2s。你每次查询都会2s并且加载的时候都会等在,这个长期等待给客户的体验是非常糟糕的。而客户能够接受的往往是第一次的等待。假如你用了缓存技术。你第一次查询放到redis里面。而后数据再从redis返回给你。后面当你继续访问这个数据的时候。查询到redis中有备份,那么不需要通过db直接能从redis中获取数据。那么,你想想,从一个key value的Nosql中取一个value能要多久呢!
所以对于像样的,有点规模的网站,缓存isnecessary的.redis也是必不可少的。并且服务端的缓存设计也是要根据业务有所区别的。也要防止占用内存过大,redis雪崩等问题。
缓存使用不当会带来很多问题。所以需要对少量细节进行认真考量和设计。笔者对于分布式的经验并不是很丰富,就相对于笔者的眼中谈谈缓存设计不好会带来那些问题。
现在不少项目,为了缓存而缓存,然而缓存并不是适合所有场景,比方假如对数据一致性要求极高,又或者者数据频繁更改而查询并不多。有的可以不需要缓存。由于假如使用redis缓存多多少少可能会遇到数据一致性问题。那你可以考虑使用redis做成分布式锁去锁sql的数据。同样假如频繁升级数据,那么redis能起到的作用就仅仅是多了一层中转站。反而白费资源。使得传输过程臃肿。
大部分场景不适合缓存一致存在,首先,你的sql数据库的内容可能很多就不说了,另外,返回给你的对象假如是完整的pojo对象还好,但是假如是使用不同参数各种关联查询出来的结果那么redis中会储存太多冷数据。占用资源而得不到销毁。我们学过操作系统也知道在计算机的缓存实现中有)先进先出的算法(FIFO);最近最少使用算法(LRU);最佳淘汰算法(OPT);最少访问页面算法(LFR)等磁盘调度算法。对于web开发也可以借鉴。根据时间来的FIFO是最好实现的。由于redis在全局key支持过期策略。
而开发中可能还会遇到其余问题。比方过期时间的选择上,假如过久会导致数据聚集。而过少可能导致频繁查询数据库甚至可能会导致缓存雪崩等问题。
所以,过期策略肯定要设置。并且对于关键key肯定要小心谨慎设计。
上面其实提到数据一致性问题。假如对一致性要求极高那么不建议使用缓存。下面略微梳理一下缓存的数据。
在redis缓存中经常会遇到数据一致性问题。对于一个缓存。下面罗列逼仄
① 读
read:从redis中读取,假如redis中没有,那么就从mysql中获取升级redis缓存。该流程图形容常规场景。一般没啥争议。

② 写1:先升级数据库,再升级缓存(普通低并发)
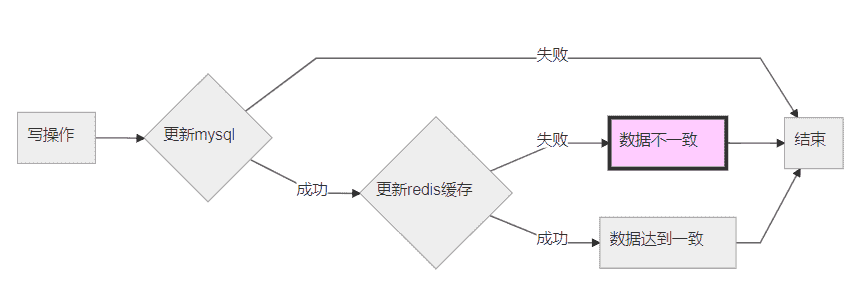
升级数据库信息,再升级redis缓存。这是常规做法,缓存基于数据库,取自数据库。但是其中可能遇到少量问题。例如上述假如升级缓存失败(宕机等其余状况),将会使得数据库和redis数据不一致。造成DB新数据,缓存旧数据。
③ 写2:先删除缓存,再写入数据库(低并发优化)
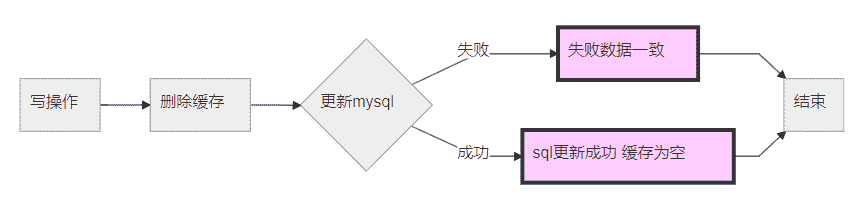
处理的问题
这种情况能够有效避免写1中防止写入redis失败的问题。将缓存删除进行升级。理想是让下次访问redis为空去mysql获得最新值到缓存中。但是这种情况仅限于低并发的场景中而不适用高并发场景。
存在的问题
写2尽管能够看似写入redis异常的问题。看似较为好的处理方案但是在高并发的方案中其实还是有问题的。我们在写1探讨过假如升级库成功,缓存升级失败会导致脏数据。我们理想是删除缓存让下一个线程访问适合升级缓存。问题是:假如这下一个线程来的太早、太巧了呢?

由于多线程你也不知道谁先谁后,谁快谁慢。如上图所示情况,将会出现redis缓存数据和mysql不一致。当然你可以对key进行上锁。但是锁这种重量级的东西对并发功能影响太大,能不用锁就别用!上述情况就高并发下仍然会造成缓存是旧数据,DB是新数据。并且假如缓存没有过期这个问题会一致存在。
④ 写3:延时双删策略

这个就是延时双删策略,能过缓解在写2中在升级mysql过程中有读的线程进入造成redis缓存与mysql数据不一致。方法就是删除缓存->升级缓存->延时(几百ms)(可异步)再次删除缓存。即便在升级缓存途中发生写2的问题。造成数据不一致,但是延时(具体实间根据业务来,一般几百ms)再次删除也能很快的处理不一致。
但是就写的方案其实还是有漏洞的,比方第二次删除错误、多写多读高并发情况下对mysql访问的压力等等。当然你可以选择用mq等消息队列异步处理。其实实际的处理很难顾及到万无一失,所以不少大佬在设计这一环节可能会由于少量纰漏会被喷。作为菜菜的笔者在这里就更不献丑了,策略只是提供大纲,具体设计还是需要自己团队实践和摸索。并且也对一致性的要求级别有所区别。
⑤ 写4:直接操作缓存,定期写入sql(适合高并发)
当有一堆并发(写)扔过来的后,前面几个方案即便使用消息队列异步通信但也很难给客户一个舒适的体验。并且对大规模操作sql对系统也会造成不小的压力。所以还有一种方案就是直接操作缓存,将缓存定期写入sql。由于redis这种非关系数据库又基于内存操作KV相比传统关系型要快很多(找值最多多碰撞几次)。

上面适用于高并发情况下业务设计,这个时候以redis数据为主,mysql数据为辅助。定期插入(如同数据备份库一样)。当然,这种高并发往往会由于业务对读、写的顺序等等可能有不同要求,可能还要借助消息队列以及锁完成针对业务上对数据和顺序可能会由于高并发、多线程带来的不确定性和不稳固性。提高业务可靠性。
总之,越是高并发、越是对数据一致性要求高的方案在数据一致性的设计方案需要考虑和顾及的越复杂、越多。上述也是笔者针对redis数据一致性问题的学习和自我发散(胡扯)学习。假如有解释了解不正当或者者还请联络告知!
假如不理解,可能对这几个概念都不理解,听着感觉太高大上,至少笔者刚开始是这么觉得,本文并不是详细详情如何处理和完美处理,更主要的是认识和认知吧。

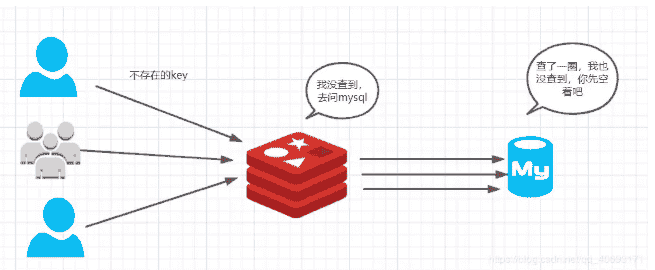
① 了解
重在穿透吧,也就是访问透过redis直接经过mysql,通常是一个不存在的key,在数据库查询为null。每次请求落在数据库、并且高并发。数据库扛不住会挂掉。
② 处理方案
可以将查到的null设成该key的缓存对象。
当然,也可以根据显著错误的key在逻辑层就就行验证。
同时,你也可以分析客户行为,能否为成心请求或者者爬虫、攻击者。针对客户访问做限制。
其余等等,比方看到其余人用布隆过滤器(超大型hashmap)过滤。
① 了解
雪崩,就是某东西蜂拥而至的意思,像雪崩一样。在这里,就是redis缓存集体大规模集体失效,在高并发情况下忽然使得key大规模访问mysql,使得数据库崩掉。可以想象下国家人口老年化。以后那天人集中在70-80岁,就没人干活了。国家劳动力就造成压力。

② 处理方案
通常的处理方案是将key的过期时间后面加上一个随机数,让key均匀的失效。
考虑用队列或者者锁让程序执行在压力范围之内,当然这种方案可能会影响并发量。
① 了解
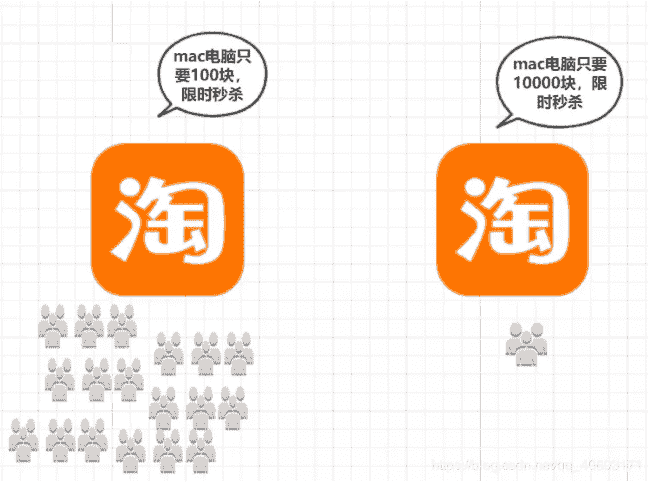
击穿和穿透不同,穿透的意思是想法绕过redis去使得数据库崩掉。而击穿你可以了解为正面刚击穿,这种通常为大量并发对一个key进行大规模的读写操作。这个key在缓存失效期间大量请求数据库,对数据库造成太大压力使得数据库崩掉。就比方在秒杀场景下10000块钱的mac和100块的mac这个100块的那个订单一定会被抢到爆。所以缓存击穿就是针对某个常用key大量请求导致数据库崩溃。
② 处理方案
能够达到这种场景的公司其实不多,我也不清楚他们的具体解决方法,但是一个锁阻拦请求总是能防止数据库崩掉吧。
其实缓存看起来,了解起来看似简单然而实际上的设计方案非常有学识。在细节设计上还会遇到消息队列、布隆过滤器、分布式锁、服务降级、熔断、分流这些。在缓存解决上甚至还有缓存预热(提前缓存部分热点数据防止刚开始缓存一律命中导致服务崩掉)等其余热门名词和问题这里就不做详情了。
最后:一波读者小福利~
读到这的朋友还可以免费领取一份收集的Java面试资料和Java核心知识体系文档及更多Java进阶知识笔记和视频资料。
欢迎做Java的工程师朋友们加入合作Q群:【 java架构技术交流,578486082 】
群内提供免费的Java架构学习资料(有高可用、高并发、高性能及分布式、Jvm性能调优、Spring源码,MyBatis、Netty、Redis、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点的架构资料)
