
小说爬虫是一种自动获取小说内容的程序,是搜索引擎的重要组成部分。不得不说Java的生态真的好,原来我以为爬虫是只能用Pyhton来写的,结果发现Java的爬虫框架不要太多……
刚开始写的时候就觉得维护起来比较麻烦,当时就在构想怎样实现通用的小说爬虫,现在有了思路,动手写了下,试了10多个网站都还是效果不错。

原理
老套路:提取小说目录的链接,而后通过链接解析正文
解析方式:正则表达式
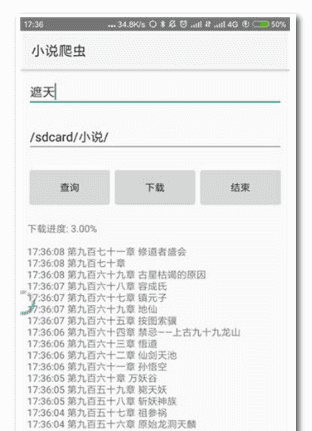
首先抓取目录链接地址

这个抓下来的url可能会带有几个不是目录页面的,这个可以过滤掉,我没有过滤,不过我的思路是可以比较url的长度来剔除部分,而后就是比较类似度。具体实现看自己
运行图

通过url抓正文

简单的使用正则来实现的,运行结果

这个实现了即可以通过目录页来抓取一本小说的一律内容了,核心全在正则,一个套则正则可能不完善,那就多来几套,思路很关键。
假如有想学习java的同学,可来我们的java技术学习QQ群:928204055,免费送整套系统的java视频教程!我每晚上8点还会在群内直播讲解Java知识,这是一个仅供粉丝朋友们学习交流的群,欢迎大家前来学习哦~不是学习Java的小伙伴非诚勿扰哦下面是部分资料截图:

欢迎关注胖胖的简书号,可视化学习java,每天升级文章,让Java学习更加简单。
公告:本文内容来源于网络,如有侵权请联络删除
