
先引入一个案例:
// 创立一个甜甜圈 //void gltMakeTorus(GLTriangleBatch& torusBatch, GLfloat majorRadius, GLfloat minorRadius, GLint numMajor, GLint numMinor); //参数1:GLTriangleBatch 容器帮助类 //参数2:外边缘半径 //参数3:内边缘半径 //参数4、5:主半径和从半径的细分单元数量 gltMakeTorus(torusBatch, 1.0f, 0.3f, 52, 26);设置一个甜甜圈,为了表现出阴影效果和立体效果,选取默认光源着色器开始渲染:
GLfloat vRed[] = { 1.0f, 0.0f, 0.0f, 1.0f }; //参数1:GLT_SHADER_DEFAULT_LIGHT 默认光源着色器 //参数2:模型视图矩阵 //参数3:投影矩阵 //参数4:基本颜色值 shaderManager.UseStockShader(GLT_SHADER_DEFAULT_LIGHT, transformPipeline.GetModelViewMatrix(), transformPipeline.GetProjectionMatrix(), vRed); torusBatch.Draw();效果如下:
 ttq00.gif
ttq00.gif可以看到,这种方式下,渲染出来的图形是有问题的,由于OpenGL并不知道图形的哪边是正面,导致我们旋转的时候把背面给转出来了,为理解决这个问题,OpenGL引入了”隐藏面消除“的概念:
在绘制3d场景时,我们需要决定哪部分是对观察者可见,哪部分是不可见的,对于不可见的部分,应该及早丢弃
先绘制场景中离观察者较远的物体,再绘制较劲的物体:如下图,先绘制红色部分,再绘制黄色部分,最后绘制灰色部分。
 image.png
image.png油画算法的弊端:
图形相互叠加的场景无法解决,如下图:
 image.png
image.png所以,油画算法对于隐藏面消除是不适用的。
原理分析:一个3d图形,你从任何一个方向去观察,最多只能看到三个面。所以,我们就没必要去渲染看不见的面,假如可以的话,OpenGL的渲染性能能提高最少%50。
OpenGL 可以做到检查所有正面朝向观察者的面,并渲染它们.从?丢弃背面朝向的面. 这样可以节约?元着??的性能.
那么问题来了:
如何告诉OpenGL哪边是正面,哪边是背面?
处理方案:(分析顶点顺序)
OpenGL默认认为:按照逆时针顶点连接顺序的三角形被称为正面,反之,顺时针进行顶点连接的三角形就是背面
案例分析:
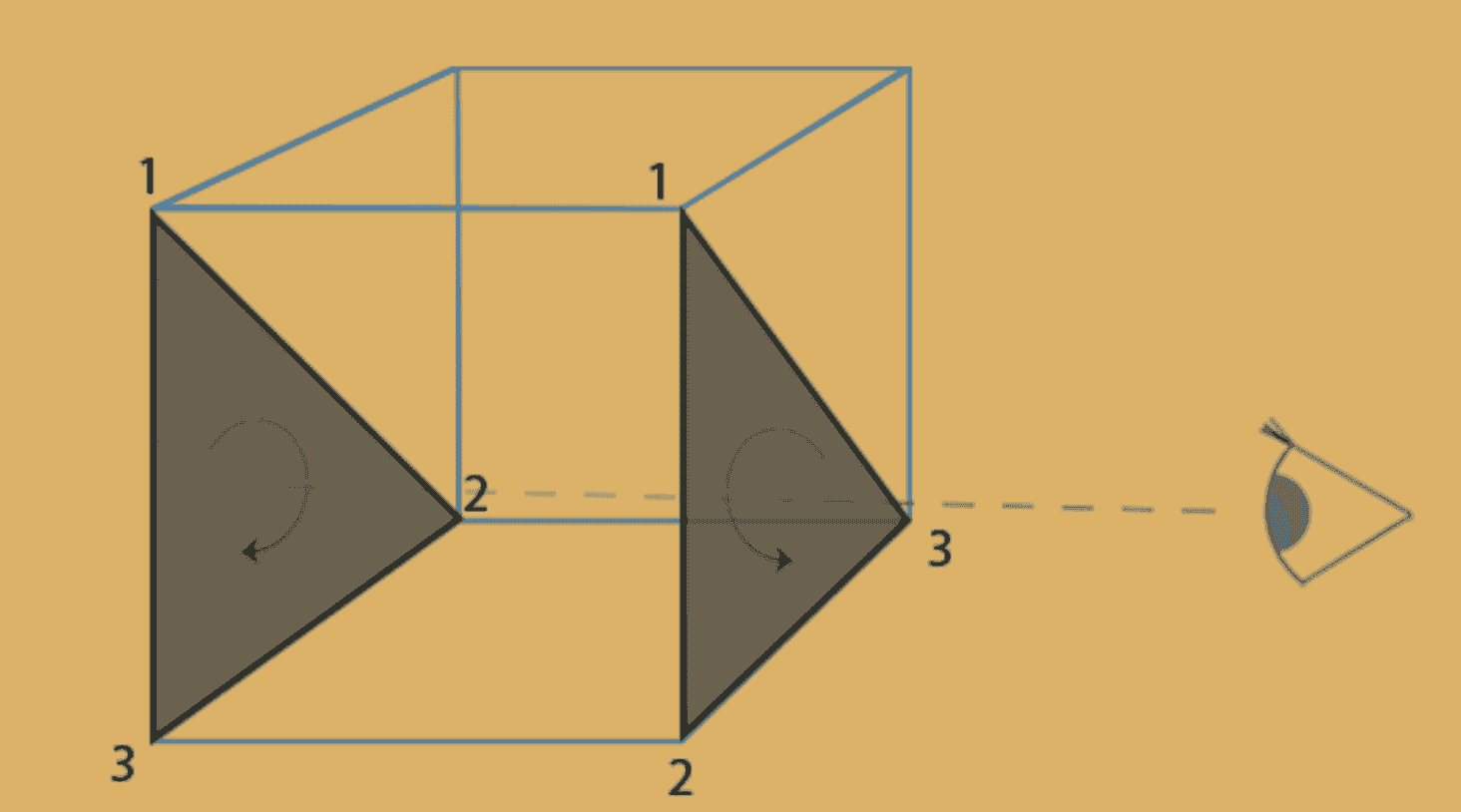 image.png
image.png当观察者在右边时,右边三角形为正面,左边三角形为背面;
当观察者在左边时,右边三角形为背面,左边三角形为正面。
所以,正面和背面是根据三角形的顶点顺序和观察者的位置共同决定的。
正背面剔除的函数示例:
//开启表面剔除(默认是背面剔除) glEnable(GL_CULL_FACE); //关闭表面剔除(默认是背面剔除) glDisable(GL_CULL_FACE); //客户可以选择剔除哪个面 :GL_FRONT,GL_BACK,GL_FRONT_AND_BACK ,默认GL_BACK glCullFace(GL_BACK); //客户指定绕序哪边为正面(可以指定顺时针为正面,不过不建议这么做)GL_CW(顺时针) GL_CCW(逆时针) glFrontFace(GL_CCW);在上面的例子中,开启正背面消除后的效果如下:
glEnable(GL_CULL_FACE); glFrontFace(GL_CCW); glCullFace(GL_BACK); //画完要取消,保证单次渲染的独立性 glDisable(GL_CULL_FACE); ttq02.gif
ttq02.gif看到,背面的黑影已经没有了,但是,仔细看!!!发现有一部分如同被咬掉了:
 image.png
image.png那么这个问题是如何产生的?又该如何处理呢?继续往下看。
什么是深度?
深度其实就是该像素点在3D世界中距离摄像机的距离,Z值。
什么是深度缓冲区?
深度缓冲区,就是一块内存区域,专门存储着每个像素点(绘制在屏幕上的)深度值。深度值(Z值)越大, 则离摄像机就越远。
为什么需要深度缓冲区?
在不使?深度测试的时候,假如我们先绘制一个距离?较近的物体,再绘制距离较远的物体,则距离远的位图由于后绘制,会把距离近的物体覆盖掉。有了深度缓冲区后,绘制物体的顺序就不那么重要了。 实际上,只需存在深度缓冲区,OpenGL 都会把像素的深度值写入到缓冲区中. 除?调? glDepthMask(GL_FALSE) 来禁止写?。
简而言之,一个像素对应一个深度值,假如需要渲染的深度比已经存在的深度还要大,那么就不会进行渲染。这个过程就叫做深度测试。
继续上面的例子:
//开启深度测试glEnable(GL_DEPTH_TEST);//取消深度测试glDisable(GL_DEPTH_TEST);效果如下:
 yjde2-u46bj.gif
yjde2-u46bj.gif我们还可以自己设置深度判断测试的模式
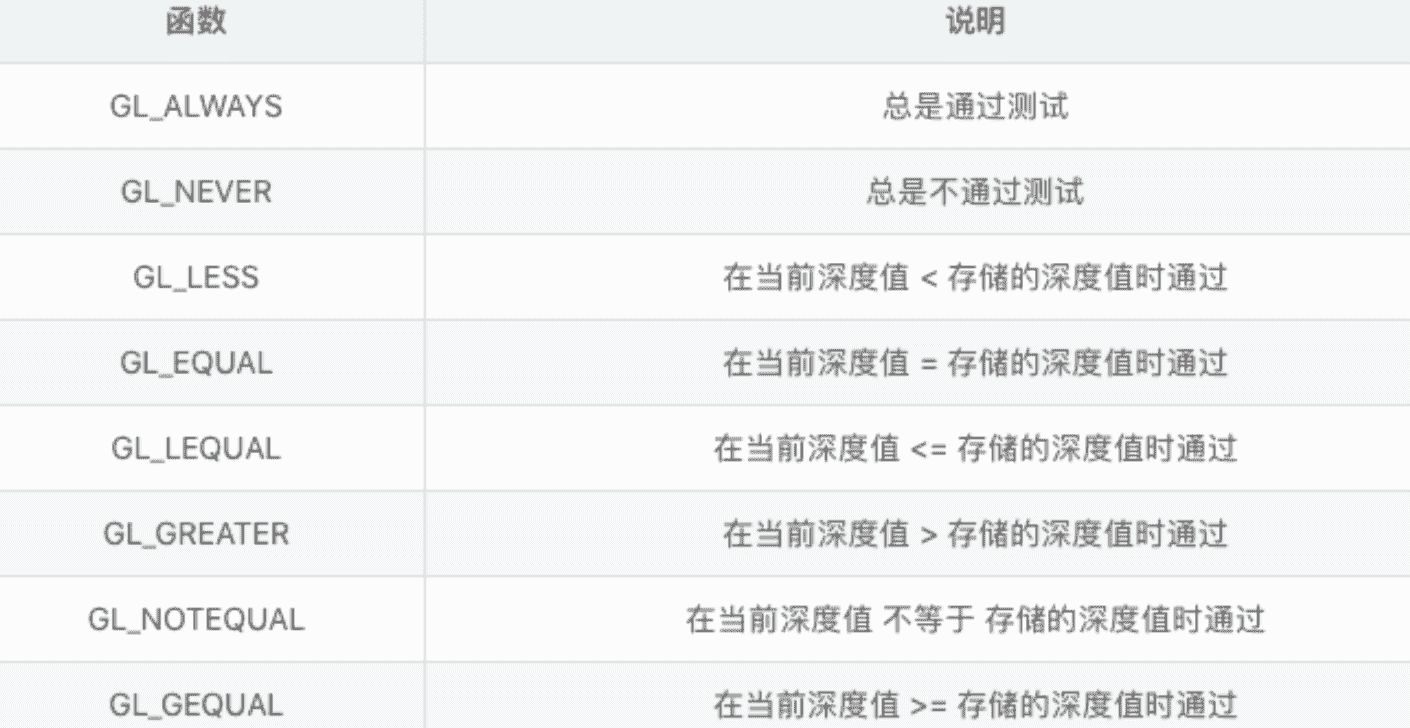 :
:开启深度测试就肯定没问题了吗?实际上还是会有两个问题:
怎样出现的?
开启深度测试后,OpenGL 就不会再去绘制模型被遮挡的部分。这样实现的显示更加真实。但是 ,因为深度缓冲区精度的限制对于深度相差?常小的情况下,(例如在同一平?上进?2次绘制),OpenGL 即可能出现不能正确判断两者的深度值,会导致深度测试的结果不可预测。显示出来的现象是交错闪烁前面2个画面,交错出现。
 image.png
image.png image.png
image.png处理流程:
/** 启用 polygon offset(多边形偏移) * 参数列表: GL_POLYGON_OFFSET_POINT :对应光栅化模式: GL_POINT GL_POLYGON_OFFSET_LINE : 对应光栅化模式: GL_LINE GL_POLYGON_OFFSET_FILL : 对应光栅化模式: GL_FILL */ glEnable(GL_POLYGON_OFFSET_FILL); //关闭 polygon offset glDisable(GL_POLYGON_OFFSET_FILL);void glPolygonOffset(Glfloat factor,Glfloat units);应?用到?片段上总偏移计算?方程式:Depth Offset = (DZ * factor) + (r * units); DZ:深度值(Z值) r:使得深度缓冲区产?生变化的最?小值 glDisable(GL_POLYGON_OFFSET_FILL);因为ZFighting并不容易随意出现,所以这里就不做演示了。这种方案只是遇到时的一种处理方案。
如何预防ZFighting
OpenGL 渲染时会把颜色值存在颜色缓冲区,每个片段的深度值也是放在深度缓冲区。当深度缓冲区被关闭时,新的颜色将简单的覆盖原来颜色缓存区存在的颜?色值,当深度缓冲区再次打开时,新的颜色?段只是当它们?原来的值更接近邻近的裁剪平面才会替换原来的颜色片段。
//开启混合 glEnable(GL_BLEND);比方我们在解决滤镜的时候,是怎样去做的呢?其实就是将原来的颜色经过肯定的算法,得到了目标颜色。这个算法就是 混合方程式:
目标颜色:已经存储在颜色缓冲区的颜色值源颜色:作为当前渲染命令结果进入颜色缓冲区的颜?值当混合功能被启动时,源颜色和?标颜色的组合方式是混合方程式控制的。在默认情况下,混合方程式如下所示:Cf = (Cs * S) + (Cd * D)Cf :最终计算参数的颜色 Cs : 源颜?Cd :?标颜色 S :源混合因子 D :?标混合因子设置混合因子:
// S:原混合因子 D:目标混合因子glBlendFunc(GLenum S,GLenum D);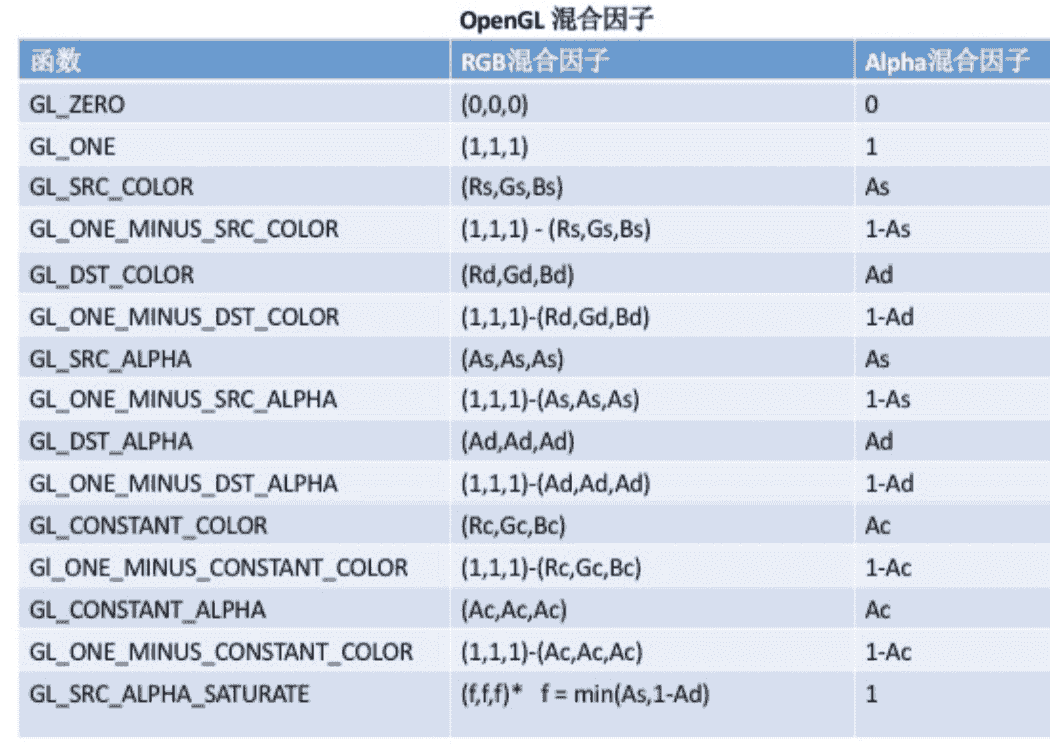 image.png
image.png表中R、G、B、A 分别代表 红、绿、蓝、alpha。
表中下标S、D,分别代表源、目标。
表中C 代表常量颜色(默认?色)。
下?通过一个常见的混合函数组合来说明:
glBlendFunc(GL_SRC_ALPHA,GL_ONE_MINUS_SRC_ALPHA); 假如颜?缓冲区已经有一种颜?红色(1.0f,0.0f,0.0f,0.0f),这是目标颜?Cd,假如在这上??一种alpha为0.6的蓝?色(0.0f,0.0f,1.0f,0.6f)Cd (?标颜色) = (1.0f,0.0f,0.0f,0.0f)Cs (源颜色) = (0.0f,0.0f,1.0f,0.6f)S = 源alpha值 = 0.6fD = 1 - 源alpha值= 1-0.6f = 0.4f混合方程式:Cf = (Cs * S) + (Cd * D)等价于 = (Blue * 0.6f) + (Red * 0.4f)总结一下:最终颜色是以原价的红色(?标颜色)与后来的蓝色(源颜色)进?组合。源颜色的alpha值 越高,增加的蓝?颜?成分越高,?标颜?所保留的成分就会越少。 混合函数经常用于实现在其余?些不透明的物体前面绘制一个透明物体的效果。
所以,我们在做开发的过程中,有少量常用的优化方案就是尽量不要使用半透明,由于半透明是需要另外做混合的算法,可能影响性能。
