

原文地址:Spark 的 RDD, DataFrame, and Dataset 三种API
https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
对开发者来说,没有什么比一套生成力高、又简单易使用,还直观和富有体现力的API更受爱戴的了。
Spark最吸引开发者的就是简单易使用、跨语言(Scala, Java, Python, and R)的API。
本文主要讲解Apache Spark 2.0中RDD,DataFrame和Dataset三种API;它们各自适合的用场景;它们的性能和优化;列举用DataFrame和DataSet代替RDD的场景。本文聚焦DataFrame和Dataset,由于这是Apache Spark 2.0的API统一的重点。
Apache Spark 2.0统一API的主要动机是:简化Spark。通过减少使用户学习的概念和提供结构化的数据进行解决。除了结构化,Spark也提供higher-level笼统和API作为特定领域语言(DSL)。
RDD是Spark建立之初的核心API。RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,并提供分布式low-level API来操作RDD,包括transformation和action。
何时用RDD?
用RDD的一般场景:
在Spark2.0中RDD发生了什么
你可能会问:RDD是不是成为“二等公民”了?或者者是不是干脆以后不使用了?
答案当然是NO!
通过后面的形容你会得知:Spark使用户可以在RDD,DataFrame和Dataset三种数据集之间无缝转换,而且只要要用超级简单的API方法。
DataFrame与RDD相同之处,都是不可变分布式弹性数据集。不同之处在于,DataFrame的数据集都是按指定列存储,即结构化数据。相似于传统数据库中的表。DataFrame的设计是为了让大数据解决起来更容易。DataFrame允许开发者把结构化数据集导入DataFrame,并做了higher-level的笼统;DataFrame提供特定领域的语言(DSL)API来操作你的数据集。
在Spark2.0中,DataFrame API将会和Dataset API合并,统一数据解决API。因为这个统一“有点急”,导致大部分Spark开发者对Dataset的high-level和type-safe API并没有什么概念。
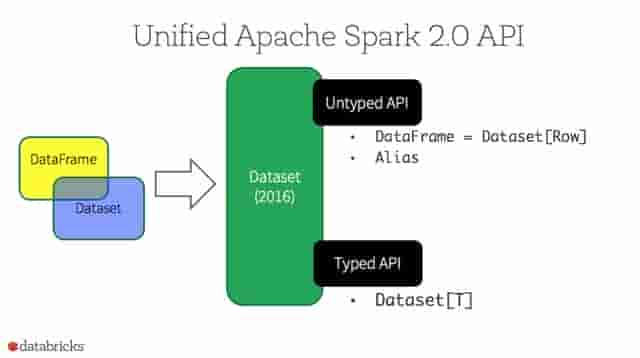
从Spark2.0开始,DataSets扮演了两种不同的角色:强类型API和弱类型API,见下表。从概念上来讲,可以把DataFrame 当作一个泛型对象的集合DataSet[Row], Row是一个弱类型JVM 对象。相对应地,假如JVM对象是通过Scala的case class或者者Java class来表示的,Dataset是强类型的。
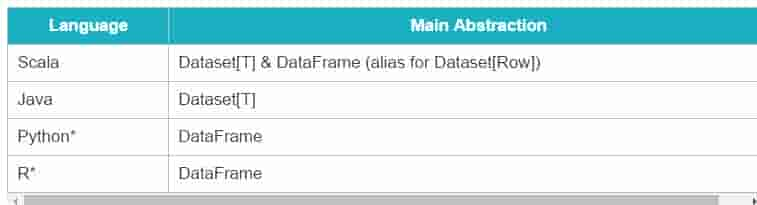
对于Spark开发者而言,你将从Spark 2.0的DataFrame和Dataset统一的API取得以下好处:
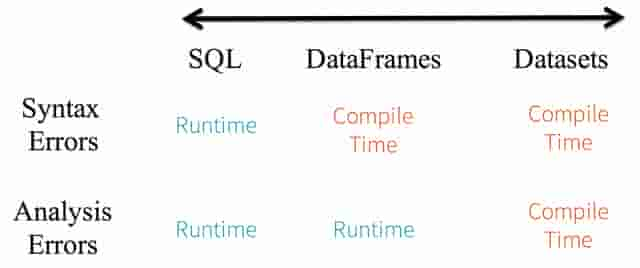
1. 静态类型和运行时类型安全
考虑静态类型和运行时类型安全,SQL有很少的限制而Dataset限制很多。例如,Spark SQL查询语句,你直到运行时才能发现语法错误(syntax error),代价较大。而后DataFrame和Dataset在编译时即可捕捉到错误,节约开发时间和成本。
Dataset API都是lambda函数和JVM typed object,任何typed-parameters不匹配即会在编译阶段报错。因而用Dataset节约开发时间。
2. High-level笼统以及结构化和半结构化数据集的自己设置视图
DataFrame是Dataset[Row]的集合,把结构化数据集视图转换成半结构化数据集。例如,有个海量IoT设施事件数据集,使用JSON格式表示。JSON是一个半结构化数据格式,很适合用Dataset, 转成强类型的Dataset[DeviceIoTData]。

用Scala为JSON数据DeviceIoTData定义case class。

紧接着,从JSON文件读取数据

上面代码运行时底层会发生下面3件事。
Spark读取JSON文件,推断出其schema,创立一个DataFrame;
Spark把数据集转换DataFrame -> Dataset[Row],泛型Row object,由于这时还不知道其确切类型;
Spark进行转换:Dataset[Row] -> Dataset[DeviceIoTData],DeviceIoTData类的Scala JVM object
我们的大多数人,在操作结构化数据时,都习惯于以列的方式查看和解决数据列,或者者访问对象的指定列。Dataset 是Dataset[ElementType]类型对象的集合,既可以编译时类型安全,也可以为强类型的JVM对象定义视图。从上面代码获取到的数据可以很简单的展现出来,或者者使用高层方法解决。
3. 简单易使用的API
尽管结构化数据会给Spark程序操作数据集带来挺多限制,但它却引进了丰富的语义和易使用的特定领域语言。大部分计算可以被Dataset的high-level API所支持。例如,简单的操作agg,select,avg,map,filter或者者groupBy就可访问DeviceIoTData类型的Dataset。
用特定领域语言API进行计算是非常简单的。例如,用filter()和map()创立另一个Dataset。
把计算过程翻译成领域API比RDD的关系代数式表达式要容易的多。例如:

4. 性能和优化
用DataFrame和Dataset API取得空间效率和性能优化的两个起因:
首先:由于DataFrame和Dataset是在Spark SQL 引擎上构建的,它会用Catalyst优化器来生成优化过的逻辑计划和物理查询计划。
R,Java,Scala或者者Python的DataFrame/Dataset API,所有的关系型的查询都运行在相同的代码优化器下,代码优化器带来的的是空间和速度的提升。不同的是Dataset[T]强类型API优化数据引擎任务,而弱类型API DataFrame在交互式分析场景上更快,更合适。

其次,通过博客https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html 可以知道:Dataset能用Encoder映射特定类型的JVM 对象到Tungsten内部内存表示。Tungsten的Encoder可以有效的序列化/反序列化JVM object,生成字节码来提高执行速度。
什么时候用DataFrame或者者Dataset?
你可以无缝地把DataFrame或者者Dataset转化成一个RDD,只要简单的调使用.rdd:

通过上面的分析,什么情况选择RDD,DataFrame还是Dataset已经很显著了。RDD适合需要low-level函数式编程和操作数据集的情况;DataFrame和Dataset适合结构化数据集,用high-level和特定领域语言(DSL)编程,空间效率高和速度快。
